网络空间测绘的生与死(一)
 iso60001 2443天前
iso60001 2443天前我们认为网络安全的核心就是攻防对抗,没有攻击就不存在防护的必要性,先有攻然后有防。比如大刀长矛、投石器、火药、轰炸机、核弹决定了盔甲、防弹衣、铜墙铁壁、以及防核碉堡。如果战争无可避免,那么攻防两端就必须相应地得到提升,否则你会被从世界上轻易地抹掉存在的痕迹。我们当然更愿意选择相信“人性本善”,但是正视“恶”的存在,是生存的前提。
关于网络安全我们提两个观点:一)攻击方式决定了网络安全技术的发展方向;二)目前阶段防守方大多抵挡不住来自黑客的攻击(我们姑且以进到内网为衡量标准)。这两个观点尤其第二个观点带有明确的实效性,随着技术的不断更新迭代,若干年后可能就会发生改变,只是在目前是比较明显的。如果让我给当前关键信息基础设施的单位的防护情况打个分,在满分100的情况下,我会打个50分,离及格还差一点。从企业角度打死不认的我见过,从攻击方角度对50分嗤之以鼻的我也见过。核心的原因是大家视角并不一致,应该说是相去甚远。
我们可以让时间往回倒退二十年,在90年代末那个互联网的早期阶段,网站的形式已经得到了广泛的发展,一些企业尝试通过注册一个域名搭建一个网站的方式来展示自己。这时候如果你问一个人“你想了解一个电影你会怎么做”?基本可以肯定他会去电影院看电影的宣传彩页,高级一点的会记下电影院的网站(早期的网民应该有过用笔记抄下一些网址的经历),去网站上了解一些信息。如果你再问“这个电影还在哪些网站上可以看到介绍?” 被问的人会骂你是“疯子”,“我怎么可能知道”。当时我也身在其中,并没有觉得这种生活有任何的不妥以及不适应。今天几乎所有人都知道用baidu就能轻而易举地得到我们要的答案,但是以我们当时的认知,很难以理解google这个“小宠物”有什么存在的必要性,它最多是个艺术品,并非生活必需品。当年的“小宠物”如今已经长成了巨无霸,而基于搜索的生活方式已经深入骨髓。
曾经一度网络安全技术人员也把Google当作安全搜索的入口,所以有一段时间Google Hacking非常时髦,大家总结了很多dorks,作为网络安全的小技巧兴奋不已。比如site:qq.com可以检索qq.com下所有的子域名网站,用”filetype:xls password“类似的方式来找一些密码,还有intitle:"Index of /"这种语法来找到目录遍历的漏洞。当年就这些小技巧,就足以把网络世界弄的哭笑不得。只是很快,那些安全研究人员就发现用Google完成的这些小的恶作剧只是个临时过程,并不代表一个真正的时代(就好比电信领域3.5G的存在是个怪胎一样)。安全技术研究人员的目标无比清晰:用最少的代价,获得最大的收益。大家不能通过google搜索到网络世界开放的数据库,也不能搜索到物联网设备(比如打印机和摄像头)。互联网的发展一直伴随着网络安全的发展,如影随形,不离不弃。所以到2008年的时候,一个安全概念已经呼之欲出,只是没人尝试去总结概念,安全人员都是实战家的进一步验证是:shodan横空出世了。
我们要深刻理解一个概念:攻击者关心的永远不是你的IP资产,而是你IP资产上对应的漏洞。漏洞也不过是一个入口,至于是破坏还是偷取数据那是以后可以从长计议的事情,至少要先打下一个入口。漏洞也不一定非得是0day,一个1day在时间差达到一个小时的情况下基本就能结束战斗了。在一段不短的时间内,攻防双方表面上达成了一定的平衡:你攻击我主要的服务器入口我就盯好主要的入口,你用漏洞扫描器半个小时扫描一个IP,我也用漏洞扫描器半个小时检查一个IP,所以大家是对等的贴身肉搏,不分伯仲。因为攻击者确实也没有特别好的方法能够比防守方更多更快的发现薄弱点。当时大家的逻辑都是:针对IP列表不定期的用全漏洞库去匹配。漏洞扫描器得到了攻防两端的共同认可是有它的道理的。
shodan出来的早期,其实并没有得到大家足够的关注,因为它当时的数据量并不完整,端口少,协议少,采集的IP少(还有一个问题是大数据引擎还不成熟)。但是在一个概念上它是非常超前的:通过对整个IPv4空间进行数据(元数据)采集,形成一个网络空间的完整数据库,研究人员可以基于这些元数据进行设备检索。举个最简单的例子,我们做一点分析就知道海康威视设备的web管理界面的server名称叫做“Hikvision-Webs”,所以如果有搜索引擎给我一个搜索界面,让我们能够对应server这个元数据字段进行检索,那么我们就能知道全球的海康威视设备有多少台。显然google并没有给我们这种机会,而且google刻意把这种设备的web portal给去除掉了,而且google对于非web协议无能为力。
即使在早期shodan没有得到广泛的关注,但是至少得到了美国相关单位的注意,因为几乎同时,在得到相关支持的情况下,SHINE项目就启动了。这个项目从2008年一直持续到2014年才结束,从一开始,他们的目标就很清晰:有多少工业控制设备/系统对互联网开放?2008年就开展了对工业控制系统的全球范围的建档建库,不可谓不超前。而支持这个项目的金主是DHS。在这里能看到,shodan的使命是搜索一切开放到互联网的设备,这是一个非常大的区别点,它一直在此聚焦,所以一方面奠定了它的领先地位,一方面也存在很多的不足,我们后续再说。
没有人会单纯到只是看看全球范围做个数据统计,因为做这个引擎从一开始基本就确定了是为网络安全量身定制,所以曾经媒体直接用最邪恶的搜索引擎来形容shodan。因为稍微懂点脑子就想明白了,如果一个攻击者掌握到一个新披露的漏洞,以前他真能针对他整理的“被攻击目标”的所有IP进行挨个的测试和确认,现在不需要了,他非但可以针对那些小范围的目标进行针对性地攻击,他也可以“顺带把全世界给黑了”。这个过程几乎是无感知的,即使是全球ipv4的数十亿IP地址(ipv6另行讨论),针对大部分漏洞而言也是一小时完成的工作量。区别在于是拿资产匹配漏洞,还是用漏洞匹配资产,前者积累的是漏洞库,后者积累的是设备指纹库,谁全谁赢。
国内最先反应过来的安全公司是知道创宇,作为一个新兴的技术型初创企业,当时他们做出zoomeye几乎是一种惯性使然,这里我必须表达我的敬意。要完成全球的数据采集存储以及检索,很自然,国内的公司马上陷入了技术demo验证期和痛苦的资源堆砌阶段,如何解决带宽问题,解决服务器高并发问题,如何解决网络被拦截的问题。好在这个时候大数据引擎技术已经得到了广泛的使用和验证,同时masscan和zmap这种全网扫描引擎的概念也得到了认可:相对老一辈集大成者nmap而言,我用少量的丢包来换取更短时间收集更全面的数据。所以,有时候晚两年也未必是坏事,可以站在巨人的肩膀上少走很多弯路,甚至有可能比老师傅走的更好。
与此同时,美国的一所高校也在做同类研究,这就是zmap的开发团队,他们顺带完成了现在的censys系统作为毕业论文。然后也顺理成章的创业并且得到了来自Google的投资。很多人感到兴奋的是看到了开放的源代码,不,我更关注的是一个趋势,代码只是一种阶段性的实现形式,并不代表了一个成品。
在我2015年出来创业时,选择网络空间测绘作为切入点就是在这种背景下诞生的:大家进入了对元数据增加的盲目崇拜和跟随。shodan是非常典型的野路子出生,效果至上,所以非常简单,十几年不变。censys把学术的严谨发挥地淋漓尽致,字段定义的眼花缭乱,极其不苟言笑地在做一个数据库。国内的厂商不断的追求更多的数据更快的更新速度,在跟随者的定位上坚定不移。我看了好久,对自己提出了一个核心问题:理论上我应该是一个深度用户,为什么很多场景下我不用?我理想的产品状态是怎么样的?
后来我就兴奋起来了,因为我当时在负责库带漏洞响应平台(也就是现在补天漏洞响应平台的前身),想要做一些技术研究和验证,这些原有的平台基本都不能满足我的需求,似乎也没人想做任何改变。比如:shodan打死不加入对域名的支持;不支持对body正文的实时模糊检索;所有的设备指纹是预置且无法保存的,规则数量少的可怜;只有硬件设备的指纹缺少应用系统的指纹。这些特性从一个技术研究者的眼里完全不可接受,但是我能理解,因为shodan的定位就是识别设备,设备不会绑定域名,设备大量的信息通过banner保存,不需要存储html元数据。所以它在原定方向上越扎越深,品牌越做越大,用户群也越来越多。技术研究人员形成了一种认知:搜索设备和数据库用shodan就足够了。
技术没有对错,只有方向的区别。不同团队对网络空间测绘的理解偏差,直接影响了后续技术突破口的不同。当然用户的需求是多种多样的,所以在不同场景下,用户的选择就会发生差异。就好像有人负责把麦子磨成面粉,有人负责把面粉做成面包,做成蛋糕,没有对错,只有场景的不同。如果你想体验做蛋糕的乐趣你就去买面粉,如果饿了想吃东西,你就买蛋糕,仅此而已。shodan就属于面粉磨的特别好的那种(至于有没有做成包子以后再讨论)。
我给网络空间测绘的使命定义是“构建网络空间的攻击面地图”,它能回答四个主要问题:互联网有多少存活IP?它们分别对应什么样的设备或者应用?它们有哪些被攻击的脆弱点?它们归属于哪个重要归属单位?我套用一个例子来说明:某一天Cisco出了一个漏洞,对外开放的cisco设备有6万台,其中3万台存在漏洞,并且有漏洞的包含某部委。能给出这个链条的就可以说掌握了核心技术,全面性和准确性决定了核心竞争力。大家会说好像第一个问题你没提到啊?对的,第一个问题是基础的基础,如果没有第一个ip的采集,你怎么知道全网的6万台?另外,网络安全一定是考虑投入产出比的,攻击的目标一定是高价值资产,所以识别归属单位是一个很重要的指标。
第一个针对存活IP扫描的任务,实在太基础了,不论是用masscan还是zmap,或者是用nmap甚至是自己实现,基本上大家都会有。只是大家在端口数量和协议识别的深入度上,大家有所不同,比如很多平台至今不能识别Oracle数据库的协议,这个很诡异。目前shodan支持300多个端口200多种协议,没有任何平台能做全网65535全端口的扫描,在ipv4都是一个不可能完成的部分,更不论说是ipv6了。一般不是很懂技术的同志不太好区分这部分的不同,这就给一些李鬼留了很大的投机空间。这里面的坑很多,比如如何稳定的扫描而不被投诉这一条基本上没法杜绝。还有用nmap做全网扫描的,也就是一个笑话,时间成本太高,做小范围可以,大范围更新就太慢了。
在大量新进入者还在想办法解决全网元数据更新的情况下(没有几个月的探索期进不了稳定阶段),其实网络空间测绘很快的进入了第二个阶段:绘制IP的攻击面。每一个步骤基本上是环环相扣,这里提到一个非常重要的名词:攻击面。这个名词也决定了未来大家方向的决定性不同。我们可以理解攻击面是所有可能攻击点的集合,一个企业暴露所有的攻击点的集合就是一个企业的攻击面,比如设备,应用系统,域名,甚至是个人。那么具体到一个IP的攻击面可不止是一个设备这么简单,从攻击者的角度可不去攻击一个浪潮服务器,而是对应有攻击入口的接口。我们在测绘过程中要输出的是一个完整的五个攻击层:硬件层,操作系统层,服务层,支撑层,应用层。比如一台浪潮服务器,安装了centos操作系统,安装了apache的网站服务器,用了stucts2的中间件,搭建了一个用友OA的业务系统。这不是一个攻击点,这是至少5个攻击点。
讲到这里,我们构建的网络测绘系统有一个非常核心的任务:识别互联网存在的所有设备和应用系统。shodan公开能识别的设备有数百种,nmap预置的设备有1800多种,加上应用有6000多种。这里并不覆盖我们非常常见的系统,比如用友OA,coremail邮件系统,深信服的VPN,也不识别金蝶的财务系统。我为什么这么提?因为几个月前这几个系统的漏洞把行业弄得个腥风血雨。互联网有多少个业务系统?有多少种设备?少说有上百万种吧。这就是为什么我们的fofa平台为什么死抓规则集(又叫指纹集)。这个任务量太大了,也是未来的核心PK指标。
应用的识别是fofa平台最先提出来的,我们设计的时候做了两个假设:一)我们假设用户比我们更懂业务系统,比如我们怎么可能拍脑袋想象出一个核能发电的设备应用呢?二)我们假设用户在看到一个设备的时候,有欲望去检索互联网同类设备的分布情况,以及有搜藏与分享的意愿。基于这两个假设,我们就给出结论:只要我们做好了完整深入的元数据整理,我们就能建立一个行业内最完善的业务规则库,就能吸引更多的人来使用和贡献规则库,从而形成一个良性循环。

稍微汇报一下我们的成绩,如下四个图对应了四个平台的alexa排名情况(仅供参考),fofa第三,zoomeye第四,shodan遥遥领先,censys其次。作为一个极其细分领域的工具类平台,shodan排名17000的高度是比较恐怖的。fofa平台的用户停留时间最长,达到15分钟,差不多是其他平台加起来停留时间的总和;同时我们的增长数是稳定且快速的。区别于其他平台,我们98%都是国内用户,并没有开始对国外宣传。我们是国内最大的网络空间搜索引擎。
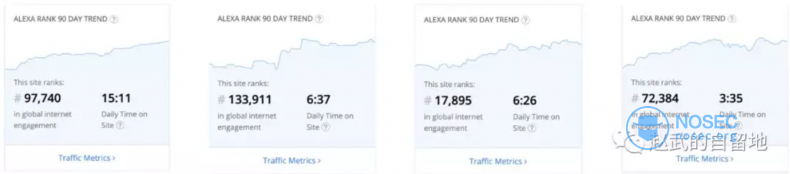
到今天,我们可以比较确信地说,我们假设的价值通过几年的验证,得到了大家的认可,目前的自增长情况比我们预期的要快,越来越多的国外用户进入到fofa。大家对fofa的认知分成两个重要的组成部分:针对特定目标的互联网暴露攻击面的梳理,以及针对单个IP的攻击面刻画。至于针对特定漏洞的全网应急,这看似是个强需求,实际上并不是广泛基础需求,这并不符合我们最初的预想。实际上,fofa的用户主要分为三类用户群体:独立的安全研究人员,乙方的安全服务公司,以及甲方的大型企业。除去我们预设的几种基础场景,这批不按常理出牌的用户给我们指出了非常多的新玩法,我们也留到后续分析。
到这里,我给一个定性:抛开广泛的用户群体使用的公开平台来提网络空间测绘,是一种拍脑袋的自嗨。在缺少大量数据补充和校验的情况下,这就是井底之蛙,你根本看不到全局的数据,你能想象的空间实在太狭窄。好比你说你能做google,“不就是爬虫嘛,能有多难”,这极大的体现了一种无知,你连人家买硬盘的钱都不具备,所以你不知道在那种大数据的视角下是诞生什么样颠覆式的新产品。做网络空间测绘是一个大数据积累的工作,需要持续投入,大量投入,投几千万也就只打了个基础。在未来,谁掌握了空间地图,谁就能指点见山。
◆来源:赵武的自留地
◆本文版权归原作者所有,如有侵权请联系我们及时删除



最新评论