FOFA大数据量拉取的最佳方案
 Newbee123 1112天前
Newbee123 1112天前
用户痛点
我们目前的FOFA API接口使用的是Elasticsearch的Start/Size机制,这种机制对于深度翻页来说不太友好,当用户尝试进行多频次的翻页调取大数据量的获取过程中,可能会因为网络波动或ES卡顿等各种问题导致进程出现问题,无法进行大批量的数据获取。如何进行有效的大批量数据获取,是当前我们需要解决的问题。
解决方案
我们直接看目前新的解决方案,一种满足高效率的大数据量一次性获取,一种满足接入程序的大数据量批量实时获取。
1. 页面下载
对于没有实时要求,需要大数据量一次性获取的用户来说,页面下载是最稳定的一种方式。满足最高单次1000万数据量的下载,一键直接下载获取大数据。1000万条数据时间大约需要1小时40分钟,以压缩包的形式获取。他相对而言时间比较久,但更为稳定。
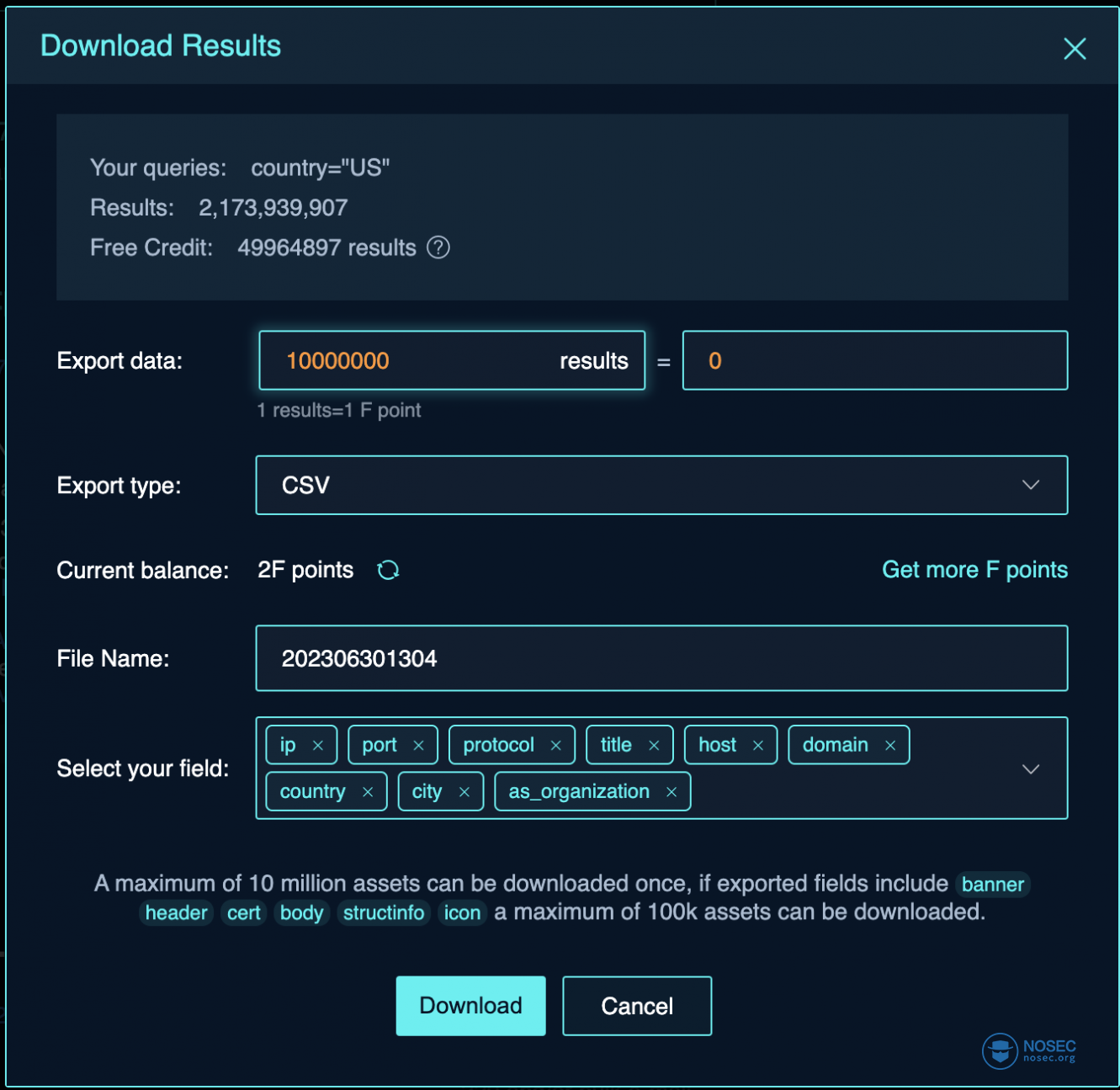
注:当导出的字段包含banner/header/cert/body/structinfo/icon这种大字段的时候,最多支持单次10万条数据下载。
2. Search After接口
但是当你需要的是接入程序的大数据量批量实时获取时,Search After接口可以作为你的选择。
当针对同一搜索语句进行大规模数据获取时,可使用连续翻页接口。该接口可以持续获取所有数据,支持失败重试,无需担心数据错位。
这个接口和基础接口的区别在于,不使用page进行翻页,引入nextid进行翻页。每次相应结果中会返回此值,不回传nextid时,默认返回第一页数据。
官方API文档地址:FOFA API Document
专用接口➡️连续翻页接口
以curl返回为例:
curl -X GET "https://fofa.info/api/v1/search/next?qba se64=dGl0bGU9IueZvuW6piI%3D&size=10&email=your-email&key=your-key&next=id"
懒得自己改?也没问题,我们已经完成了该接口在官方Python的SDK库的更新,通过命令行进行执行即可。下面是地址和演示:
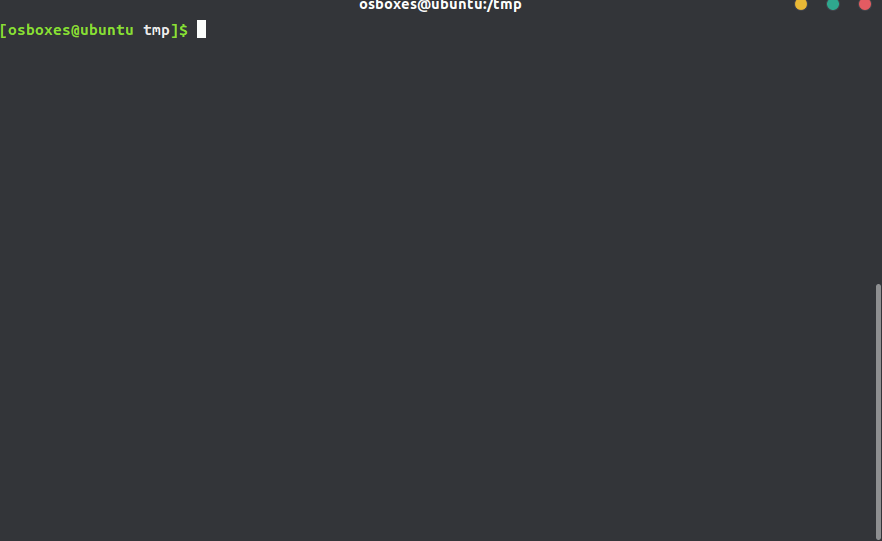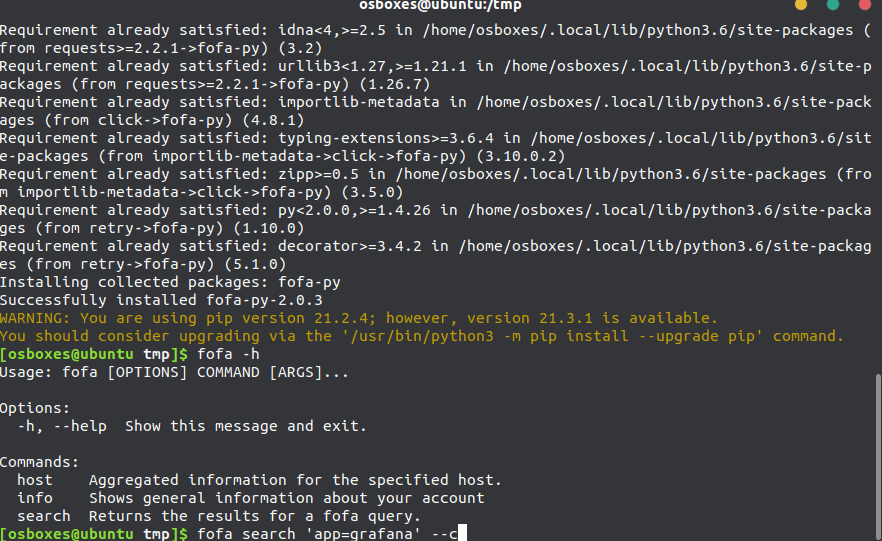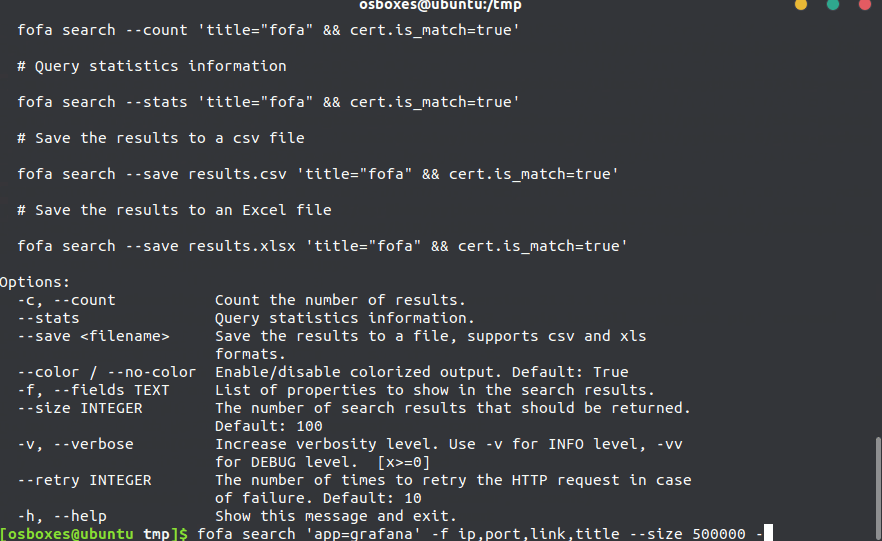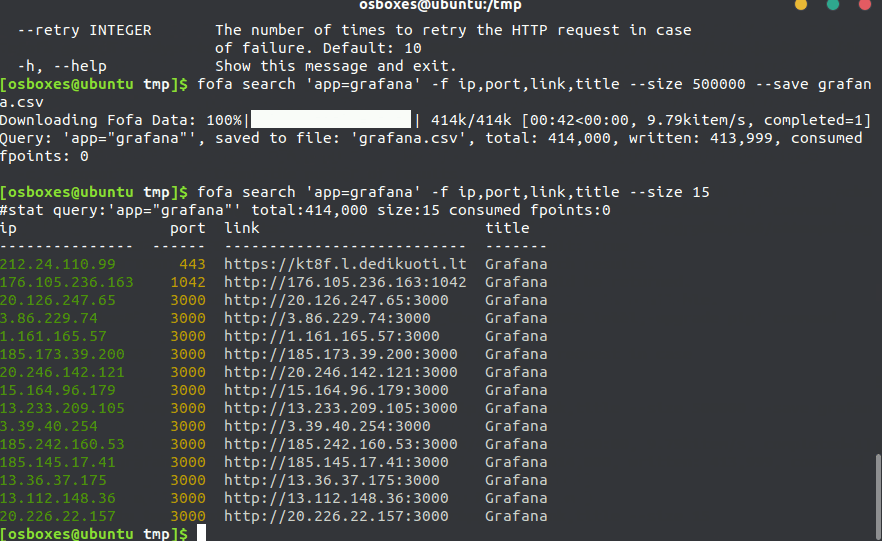
我们可以从演示的动图中看到,该SDK不仅支持大数据量导出任务一次性下发,同样也支持实时动态资产调取,比普通的接口更加的稳定。
我们可以在Python的SDK库地址 或通过官方的github地址进行更新使用。
解决思路
第一个一次性获取大量数据使用页面下载很好理解,点击下载然后等待获取即可。我们只需要解决下载包压缩的问题。
第二个满足接入程序的大数据量批量获取;坦白说这是一个很占用资源的方式,我们也可以进行限制即可,不用费时费力去做,但是用户至上一直是我们的目标。通过市场的调研和行业的最佳实践,我们最终选择了Search After方案。
Elasticsearch共推荐了两种解决方案:Scroll和Search After方案。
根据他的官方描述:结果的分页可以通过使用from和size参数来实现,但当达到深层分页时,成本变得难以承受。index.max_result_window默认为10,000,它其实是一种保护机制,搜索请求需要堆内存和与from+size成比例的时间。Scroll API被推荐用于高校的深层滚动,但滚动上下文的开销很大,不推荐其用于实时用户请求。Search After参数通过提供一个活动游标来解决这个问题,其方式是使用上一页的结果来辅助获取下一页的结果。Search After并不是一个可以自由跳转到随机页面的解决方案,而是可以同时滚动多个查询的方式。
通过行业的调研和官方的解决方案,我们进行了分析及实验尝试,其中Scroll需要对上下文进行维护,scroll_id过期后无法继续进行翻页,且可能会因为网络不稳定等其他因素导致id失效,无法继续获取,导致导出程序中断。
Search After适用于需要分页检索数据,且实时性要求较高的场景,不需要额外对上下文进行维护,所以根据痛点的问题,我们最终选取Search After这种解决方案。
写在最后
FOFA始终秉持着用户至上的理念,深感万千白帽子师傅的支持和行业的认可对我们前进的巨大推动力。我们对您的需求和反馈充满热情,并持续致力于解决问题、保持自身的技术导向,以助您创造更大的价值。FOFA坚信,用户的满意和成功才是我们不懈追求的目标。
参考文献



最新评论