探索网络世界的利器(认知篇)
 Newbee123 1140天前
Newbee123 1140天前
▌背景概述
我们都知道,在进行资产收集时,FOFA工程师需要处理从FOFA提取的元数据,以生成所需的业务数据。在这个过程中,可能会出现各种需求,例如检测站点是否存活、快速判断页面快照等等。市面上也存在许多开源工具,用于辅助清洗和处理数据。
那么,我们如何能够快速地利用FOFA一步到位呢?今天,我们将介绍一个众所周知的工具——工作流,通过一个"开放站点查找"的工作流示例,向大家展示以FOFA上的数据为基础,你可以随心所欲地进行加工处理,得到你想要的。
▌开放站点查找
在FOFA个人中心的开放实验室中,你就可以看到这个功能啦。我们直接看视频演示。
在这个工作流中,我们都做了哪些步骤呢?通过将查询语句输入“开放站点查找”功能中,你可以快速筛选出可直接使用的网站,点击右侧的网址信息,即可跳转至导航页面。
视频中的例子,是如何实现并达到可直接使用的结果呢?1. 存活检测;2. 判定是否需要登录/激活/收费等条件;3. 页面快照;4.生成专属导航。一步到位,收集可以直接使用的站点。接下来bot就会把这个workflow进行拆解,告诉大家每一步都是用来做什么的,以及如果你更换目标之后,需要调整哪些内容,生成自己需要的目标开放站点查找。
▌功能模块拆分讲解
这就是开放站点查找所需要的全部工作流,总共11个模块拼装完成。
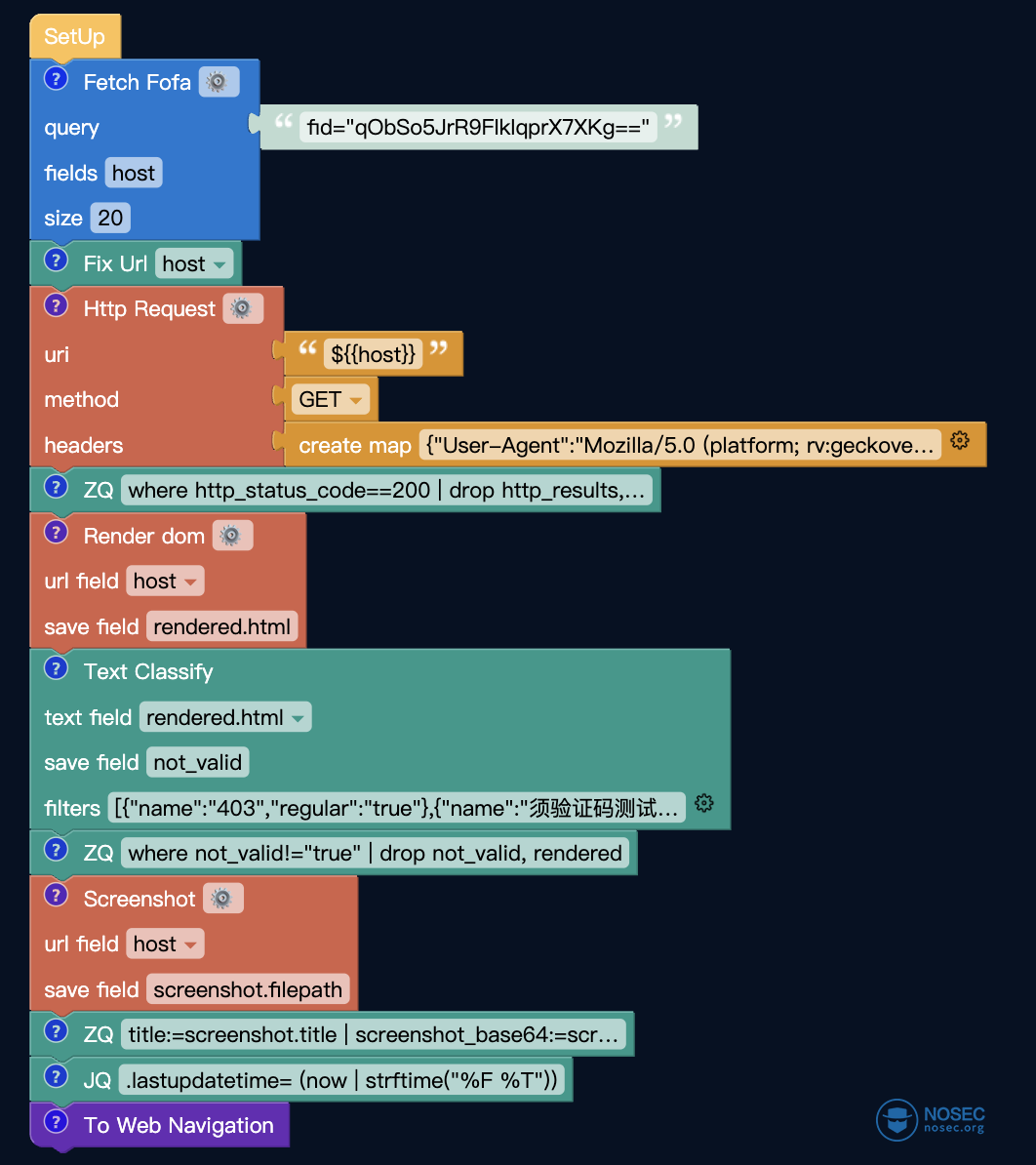
1. 模块拆分:数据导入
第一部分是最好理解的部分,将来自于FOFA的数据进行导入,可配置的包括:
- FOFA的搜索语句;
- 需要导入的字段;
- 导入的数据量;
案例中展示的FOFA搜索语句是
fid="qObSo5JrR9FIkIqprX7XKg=="导入的字段是host字段,导入的数据量是20条。

我们可以看到下面还接入了一个格式化为Url模块,这个模块的主要作用是将从FOFA拿到的host字段格式化为URL格式。这里其实你需要格式化哪个字段为URL格式都是可选的。
2. 模块拆分:存活检测
第二部分主要是对目标站点进行存活检测,由HTTP请求和ZQ语法组成。
HTTP请求模块中,第一步可以在右上角的设置按钮中设置单个资产请求时间,默认10秒。URI 为 HTTP 请求的目的地址,请求的内容为刚刚从 FetchFofa 块中获取的 host 字段对应的值。请求方式为GET,是获取的意思。
最后填入需要的请求头:
{"User-Agent": "Mozilla/5.0 (platform; rv:geckoversion) Gecko/geckotrail Firefox/firefoxversion"}就完成发包前的配置啦。一般情况下不需要进行修改。

辅助的ZQ语法为:
where http_status_code==200 | drop http_results, http_result, http_status_code意思是获取其中请求状态码为200的资产,并删除冗余字段。
这里的模块在存活检测方面已经是一个非常标准的模版了,所以对于大家来说,需要修改的部分调试请求时间即可。
3. 模块拆分:文本检测
第三部分则是进行动态渲染并进行文本检测。
3.1 网页渲染
为什么需要渲染 HTTP 页面呢?这是因为现代的网页通常包含大量的动态内容,这些内容是通过 ja vasc ript 在客户端(即浏览器)上动态生成的。HTTP请求时,默认只获取原始的 HTML 内容,而不会执行 ja vasc ript 或进行渲染,这导致获取到的网页信息可能是不完整的或缺少某些动态生成的内容。
通过渲染 HTTP 页面,我们可以模拟用户在浏览器中的行为,包括执行 ja vasc ript 代码、加载动态资源、填充表单等。这样可以确保我们获取到的网页内容是与实际浏览器中看到的一致的,并且包含了所有的动态内容和交互功能。
渲染模块同样可以进行默认渲染时间设置。如果渲染时间过短,可能会导致以下问题:
动态内容不完整:某些网页的内容是通过 ja vasc ript 动态生成的,如果渲染时间过短,可能无法完全执行 ja vasc ript 代码或加载动态资源,导致爬取到的网页内容不完整。这意味着我们可能无法获取到包含动态生成的数据或交互功能的部分内容,在这个事例中,我们可能会错过弹出 403 提示的无效网站。
缺少关键信息:一些网页可能使用 ja vasc ript 来填充表单、加载异步数据或执行其他关键操作。如果渲染时间过短,可能无法执行这些操作,导致缺少关键信息,从而影响后续的数据提取和分析工作。
错误的页面结构:某些网页在加载完成后会通过 ja vasc ript 动态修改页面结构或样式,例如添加、删除或隐藏元素。如果渲染时间过短,可能无法捕捉到这些动态变化,导致解析网页内容时出现错误或不准确。
对于每个不同的目标,我们需要根据具体的需求和目标网站的特点来决定渲染时间的合适程度。在某些情况下,较短的渲染时间可能足够获取所需的信息,而在其他情况下,可能需要更长的渲染时间以确保获取完整的动态内容。对于每个特定的爬取任务,需要进行实验和调整,以找到适合的渲染时间。
所以我们将渲染时间配置在了 Render dom 旁边的设置按钮中,大家可以随时根据自己的需求对渲染时间和请求超时时间进行修改。
3.2 文本分类
在文本分类的模块中,保存字段名叫 not_valid,直接翻译成中文就是 无效站点。
那么,我们来定义一下什么是无效站点:
- 访问了不能显示 AI 聊天框的站点;
- 访问不了的站点;
- 访问后站点报错,包括 500、403 等错误内容的站点;
- 需要登录、输入邀请码、输入验证码的站点等。
总结一下,对我们而言,不能白嫖的都是无效站点。
文本分类就是用于我们筛选掉无效站点的利器。
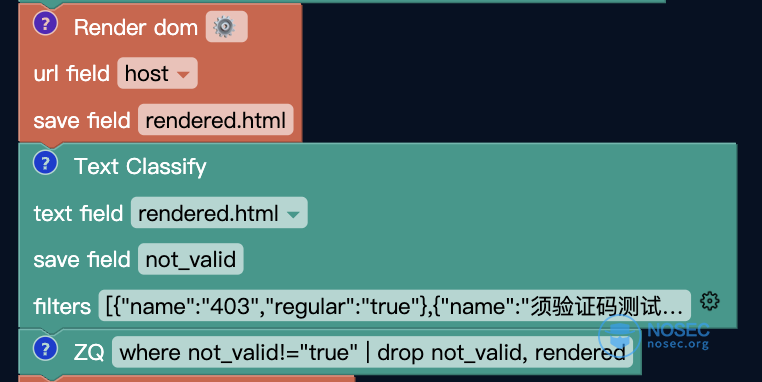
我们可以点击 filters 行最右边的过滤按钮进行过滤,将存在以下词汇的资产直接进行过滤排除,以当前的案例为例,当包含图中出现的词汇的时候,这个站点就被我们标记为不可直接使用,所以我们直接进行排除。
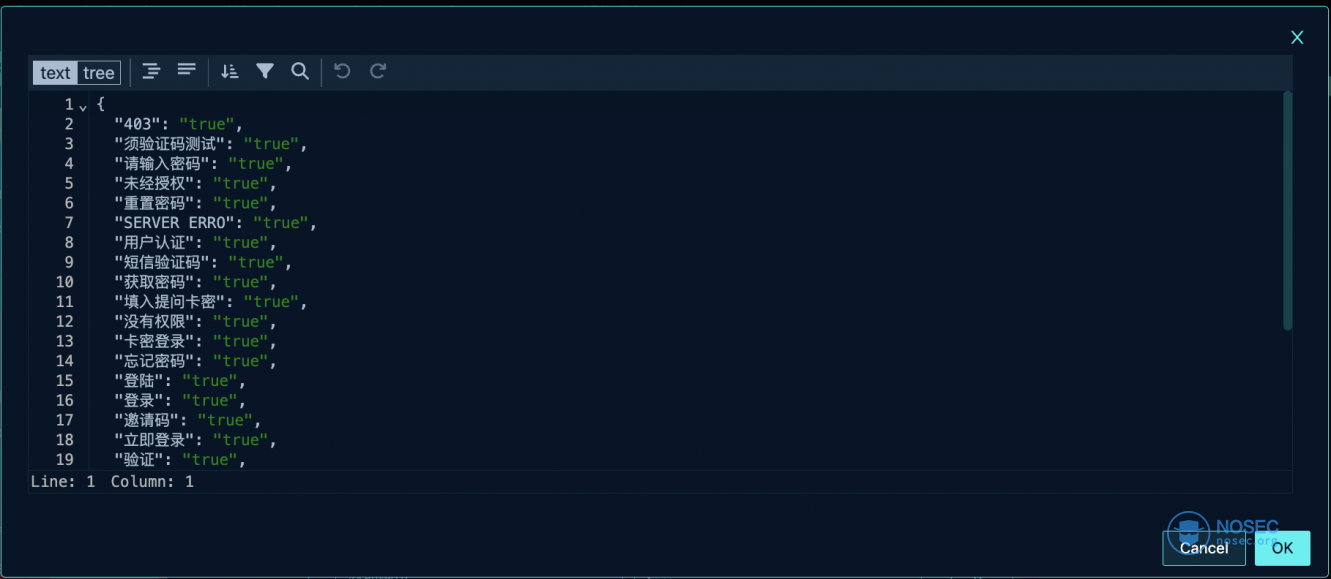
同样最后添加ZQ语法模块进行辅助,ZQ语法为:
where not_valid!="true" | drop not_valid, rendered意思为包含过滤字段的资产直接删除,剩余进行保留。
这里非常的好用,也可以单独将模块拆分出来进行垃圾资产过滤,懂得都懂。
文本分类的进一步优化
然而,只排除无效站点的效果其实并不理想,每次执行结束后,总有那么七七八八个网站是不管等多长时间都加载不出来的。
为了再次筛选掉这些内容,我们又向 not_valid 字段中添加了是否为 false 的判定,也就是有效站点的判断。
当一个网页内容经历了所有是否无效的判定后,剩下的只有空页面和有效页面,所以最后的 zq 语句中,我们筛选的是 not_valid != "true", 当然也可以改为: not_valid=="false",进一步精细化结果。
4. 模块拆分:页面快照
第四部分则是进行页面截图,当我们完成存活检测、无效资产过滤,下一步就是对剩余的资产进行页面截图,方便识别。
同样的,页面截图的默认时间可以根据自己的需求进行修改。
辅助的ZQ语法:
title:=screenshot.title | screenshot_ba se64:=screenshot.ba se64 | drop screenshot | url:=host | drop host意思为:将 Scrreenshot 输出的块格式化为 WebNavigation 需要输入的字段
辅助的JQ语法:
.lastupdatetime= (now | strftime("%F %T"))意思为保存当前的页面截图时间至文本,方便大家辨认。

5. 模块拆分:数据输出
最终的数据输出模块可以选择的,默认输出的格式为网址导航。但是也可以切换为输出为Excel表格,在左侧的数据输出进行切换即可,这一步就非常好理解啦!
这里提一嘴,我们看到其中一直有一个辅助语法穿插在工作流中间,它就是ZQ。ZQ语法的官方地址为:https://zed.brimdata.io/docs
感兴趣的小伙伴可以先行研究,当然大家也可以等我们拼接出可固化的模块直接进行使用即可。
▌写在最后
学会了开放站点查找这个工作流的原理,那么恭喜你已经入门了工作流的玩法啦!因为它真的很简单!
其实这个开放站点查找的工作流,已经包括了好几个可以进行单独拆分的场景去使用,比如单纯对数据进行存活检测、关键词筛选、数据去重等都可以进行拆分所使用。相信有些同学已经进行了工作流自主拼接,进行各式各样的操作啦。
后续我们也会对单个功能点进行拆分讲解,拆分成一个个单独的场景,帮大家更好地玩转工作流!
关于目前的计费模式来说,执行工作流每分钟扣费50F点(约等于1毛钱),当总执行时间不满10秒时不扣费。当FOFA数据的调取量大于100时,将使用各位本身账号的API进行调取哦。
对于商业版会员和企业版会员来说,我们开放了月度免费赠点模式,每月自动刷新额度。两种会员身份的用户每个月都有免费的赠点,随便畅玩开放实验室的所有功能,祝大家玩的开心~



最新评论