如何逆向分析嵌入式设备的BootLoader(U-Boot),第1篇
 匿名者 1595天前
匿名者 1595天前在本文中,我们将为读者介绍如何逆向分析嵌入式设备的引导加载程序。
简介
首先,我们对本文涉及的软硬件做简单介绍:
- CPU为ARM-Cortex A7处理器。
- BootLoader是一个定制版U-Boot(二进制文件中的符号已被剥离)。
- 我们找到了该SOC的数据手册。
- 我们从供应商的网站上下载了固件映像。
- 内核和rootfs已被加密,并且是用的加密方法大概率是“自定义的”。
- 该物联网设备没有使用ARM TrustZone。
- 该设备已强制使用安全启动。
本文的主要目标是逆向分析自定义加密函数,检索加密密钥,并解密内核映像。虽然这场冒险将以一种出人意料的方式结束,但是,我们确实设法解密了内核映像。
什么是BootLoader?
计算机启动时运行的第一个程序,就是我们所说的BootLoader,它用于加载操作系统。BootLoader通常存储在计算机硬件的EEPROM或NOR闪存(持久性闪存的一种)中。该程序的功能是初始化各种系统组件:从CPU寄存器到设备控制器和内存内容。这个引导程序需要定位操作系统,并将其加载到内存中,然后,将控制权转移给操作系统,这样,它就可以开始向系统提供服务了。
另外,某些计算机系统使用的是多阶段引导:当计算机加电时,一个位于非易失性存储器中的小型启动程序(称为BIOS)被执行;这个初始程序随后加载位于磁盘固定区域的第二个引导程序(称为引导块)。第二个引导程序比其加载器要复杂得多(想想像Grub这样的程序,具有好几千行代码),它需要完成大量的工作,设置足够的支持,以便为加载操作系统做好准备。
对于多阶段引导过程实际示例感兴趣的读者,请参阅https://microchipdeveloper.com/32mpu:boot-sama5d2-series#toc4。
虽然这里并不会讨论Das U-Boot实现的技术细节,但U-Boot的确是一个主打嵌入式设备的开源主BootLoader。
注意:“主BootLoader”并不意味着U-Boot必须是第一级BootLoader,它可以用于引导的任意阶段。
提取固件
下载固件后,我首先尝试通过Binwalk来提取它。

不幸的是,这并没有达到预期的结果,因为它无法识别(预期的)各种分区,所以,提取工作也就无从谈起了。
这通常意味着这些文件可能以某种方式被加密,或者采用了自定义格式——这种情况的可能性不大。我们可以通过检查单个文件的熵来验证第一种假设。对于没有加密的二进制文件来说,某些指令出现的频率通常很高(如序言、nop序列等),而数据结构几乎没有随机性。此外,教长的零序列在数据段中也很常见。相反,而对于经过加密的文件来说,则拥有近乎完美的熵,因为这是稳健的加密方案的目标之一。
为了进行这项检查,我们可以使用Binwalk --entropy标志,来检查所有固件文件的熵。如你所见,大多数文件的熵值(对应于Y轴)几乎都是1,这表明这些文件都是经过加密处理的。
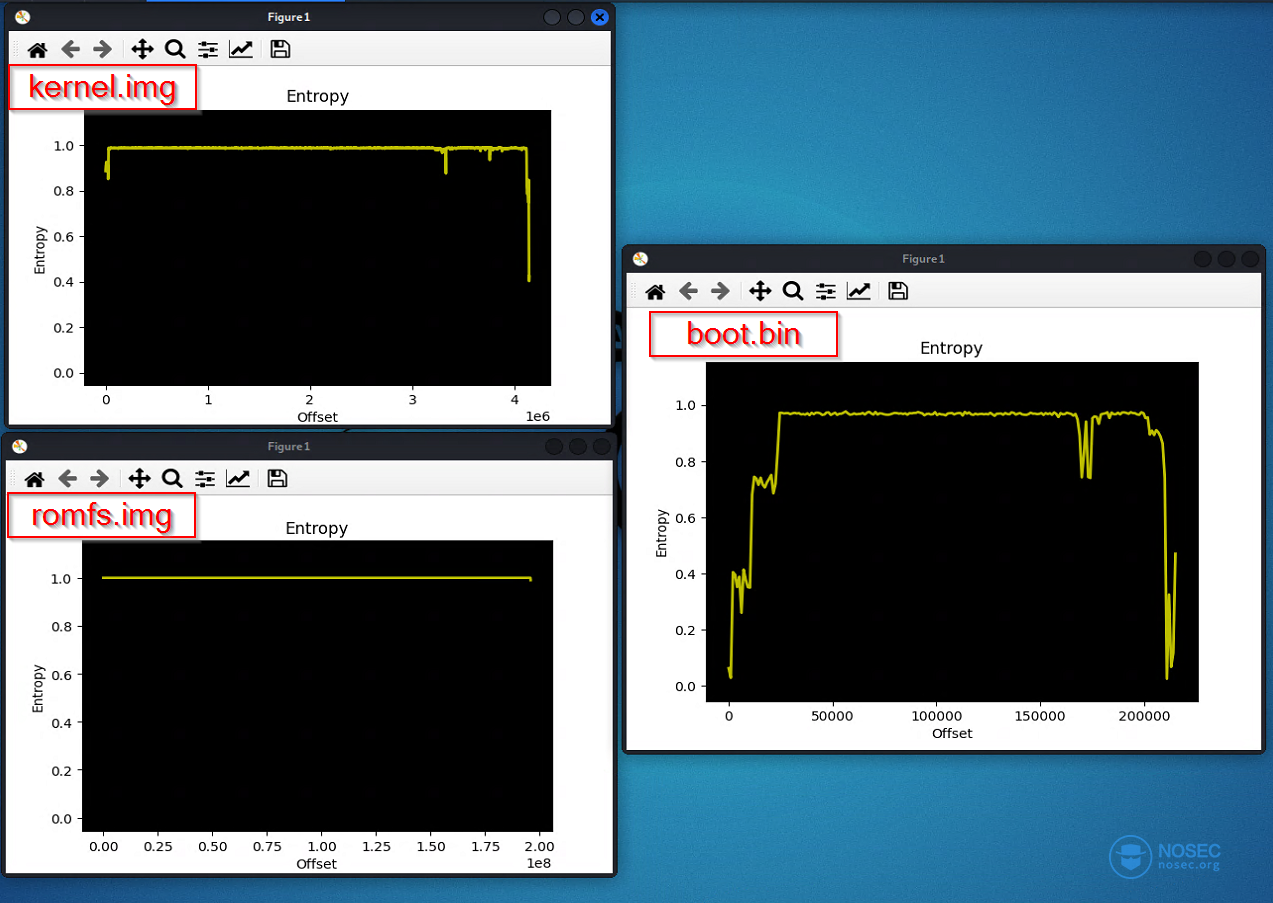
相反,boot.bin文件却很特别,因为它的熵并不总是保持在高位。看到那些取值较小的熵值吗?这就是我们谈到的重复现象所致。因此,我们可以合理推测:在启动过程中,在开始执行内核之前,明文形式的BootLoader就是负责解密其他分区的代码。不过,我们仍然不知道BootLoader中有多少解密逻辑:它可能解密所有的部分,也可能只解密内核部分,然后,由内核使用自己的密钥/算法来解密文件系统的其他部分。实际上,后一种方法在加密链和验证链中都不罕见。
带着这个假设,我们用Binwalk(即binwalk -efirmware.bin)从固件中提取了引导映像,然后,再次运行Binwalk来提取boot.bin文件。
让我们运行strings boot.bin,以确保我们没有完全疯掉。
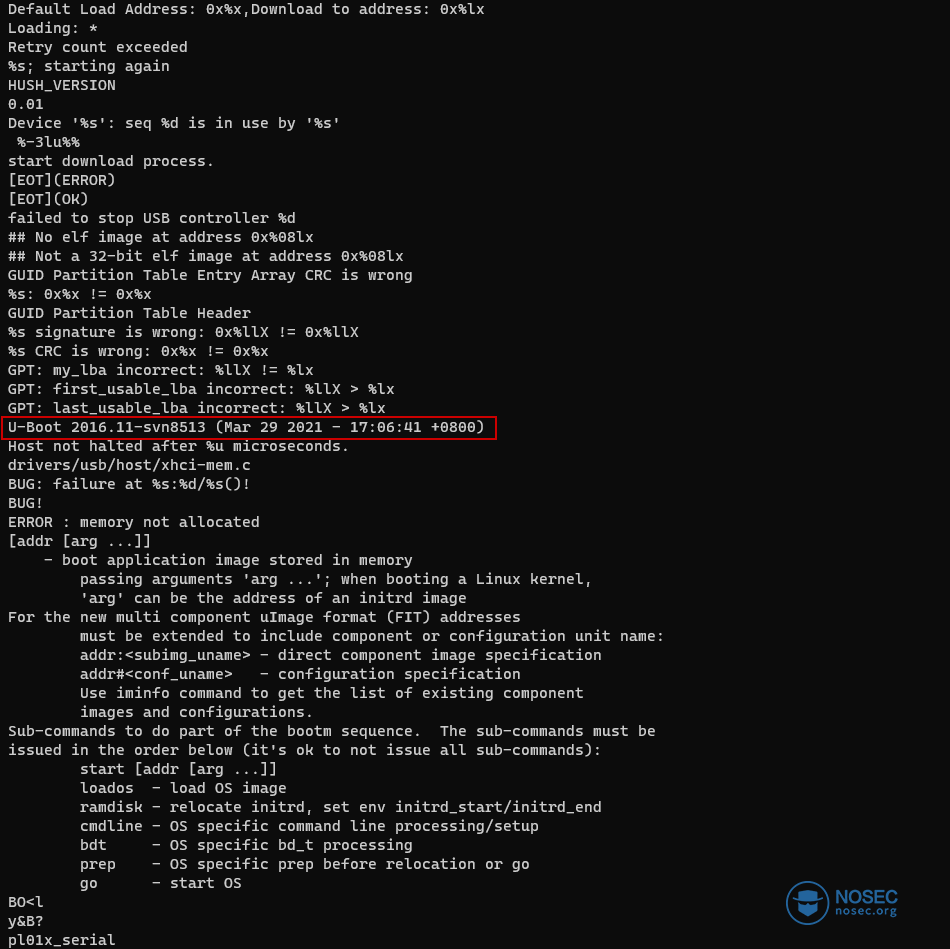
很好,我们得到了U-Boot的二进制代码!下面,让我们检查引导参数:stringsboot.bin grep args。
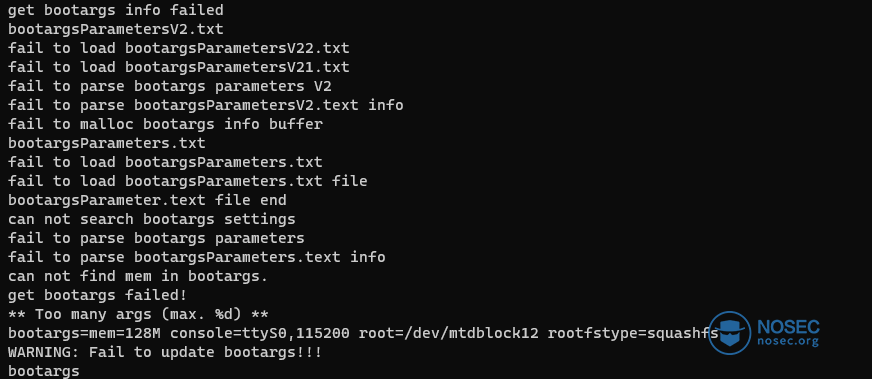
没什么特别的,但是现在我们知道squashfs rootfs的存储位置:/dev/mtdblock12。
我们还能了解点什么?好吧,让我们寻找一些地址来了解这个程序在内存中会是什么样子。通过查看数据手册,我们发现了一个映射所有设备地址的表——如果您熟悉ARM的话,这并不奇怪——RAM的起始位置为0x8000_0000。
接下来,让我们执行命令strings u-boot.bin | grep 0x:
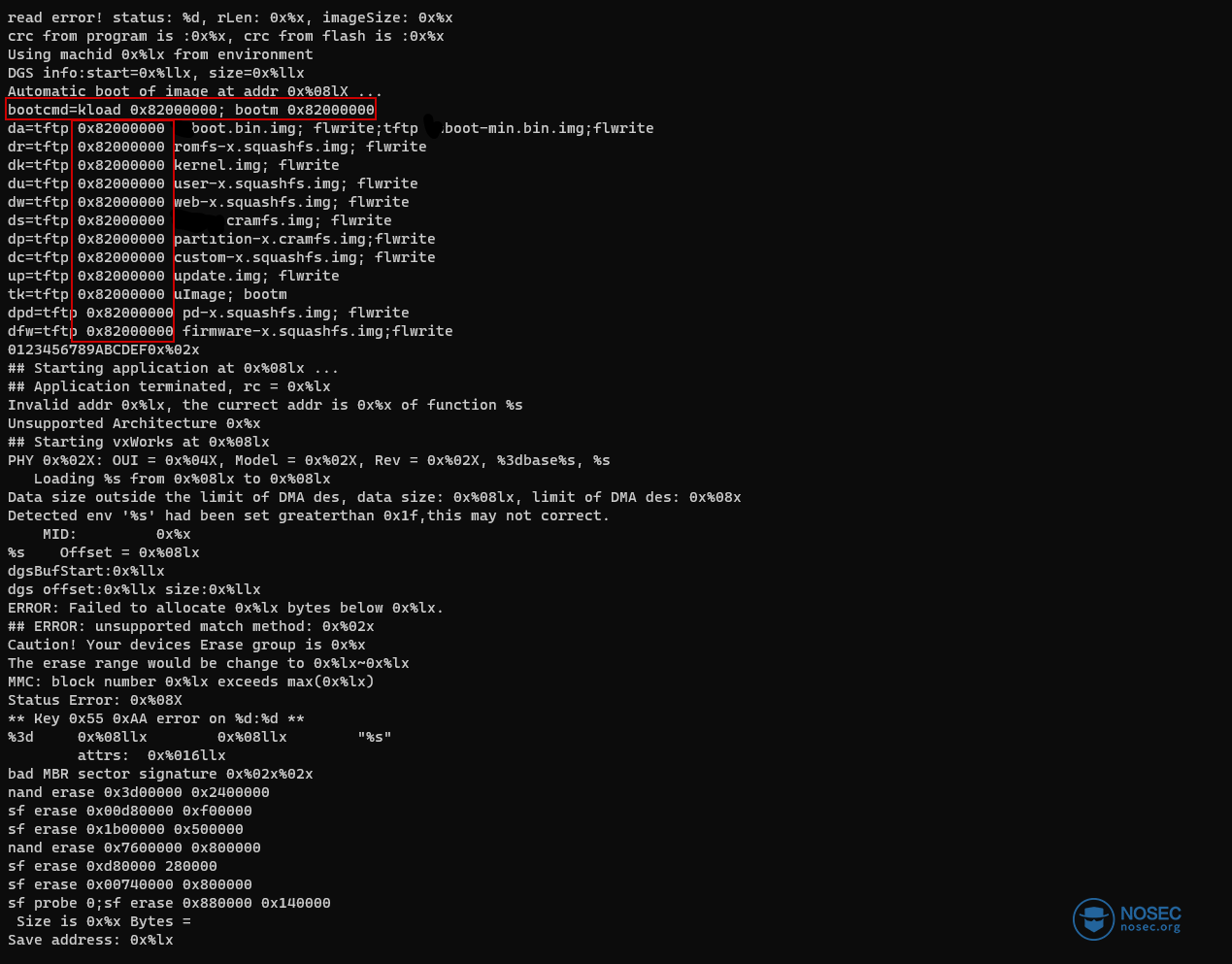
好的,如果RAM是从0x8000_0000处开始得,那么,将内核加载到0x8200_0000处就无可厚非了。但是,从0x8000_0000处加载到0x8200_0000处的是什么呢?U-Boot装到哪里呢?它应该加载到固定的地址,因为它是BootLoader!
Zi0Black:我刚刚参加了大学操作系统课程的考试,我对此非常有信心。我本可以更深入地研究数据手册或其他文档来找到答案,但我选择了不同的方法。
深入分析裸机二进制文件(ARM)
二进制文件是计算机所加载和解释/执行的内容。就其本质而言,它们只是一连串的字节,被放置在内存中,并有足够的信息来启动执行。在现实中,由于系统提供了对于动态链接、共享库、运行时重定位等机制的支持,以至于当我们在一个系统上编译二进制文件并在另一个系统上运行时,或者在安全更新后看到系统直接使用修复后的代码库时,我们几乎认为这些灵活性是理所当然的。除此之外,一个程序需要做一些有用的事情来实现其存在的意义(是的,让我们从哲学的角度来看)。为了实现这一点,它很可能需要与系统进行交互,分配一些内存,也许还需要向磁盘存储一些数据。当然,我们并不期望所有的二进制文件都能实现这种逻辑:操作系统可以为它们提供这些服务。
我们刚才描述的景象,就是您在Linux环境下运行的ELF文件时通常会遇到的情况。当然,建立所有这些生态系统需要付出高昂的成本:需要一个功能完备的操作系统,一个动态链接器和所有的程序库。在物联网或其他内存受限的环境中——或者在您不想要建立所有这些抽象层的情况下(例如专用的云工作负载或类似的情况)——可以让单个二进制文件实现它所需的一切功能。这就是裸机计算(BMC)的核心思想。在BMC范式中,应用程序的运行不需要任何操作系统(OS)或集中式内核的支持,也就是说,在运行应用程序之前,不需要在裸机上加载中间软件。
在BMC范式下,我们使用的是一个硕大的静态平面文件,它能够直接启动运行,管理内存,处理中断并(如果需要)直接访问硬件。对于这些二进制文件来说,由于它们是唯一处于执行状态的实体,所以,不必实现任何形式的虚拟内存,因为确实没有需要实现“隔离”,也没有必要用某种形式实现内存的分页——所有内存都是它的。这就意味着,当我们处理裸机二进制文件时,我们通常会在常规情况下(例如ELF文件)运行时解析重定位的地方发现很多关于内存布局的信息。不用说,U-Boot就是一个裸机二进制文件。
关于中断
在进入目标二进制文件并了解其结构之前,让我们先简单地介绍一下中断问题。
硬件组件可以随时通过向CPU发送信号来产生中断,通常是通过系统总线(一个处理系统中可能有许多总线,而系统总线则是核心组件之间的主要通信路径)。中断还用于许多其他目的,对操作系统和底层硬件之间的通信至关重要。当CPU收到一个中断信号时,它会立即放下手头上的工作,并立即跳转到某个固定的内存区域。
应该注意的是,由于中断处理程序的执行而改变上下文的背后并没有黑魔法,除了CPU的特性(例如,一组额外的寄存器为程序员节省了一些上下文切换的繁重任务)。中断处理程序负责保存当前状态/寄存器(上下文),并在服务完成后恢复它们,以正确地恢复中断指令流的执行。
这个“内存区域”基本上是一个固定长度的条目表,这些条目要么保存专用中断服务例程的地址,要么直接保存专用中断服务例程的第一条指令。根据每个条目的大小和格式,某些指令可以直接存储在那里。这些指令有可能足以完全处理中断,也可能不足以完全处理中断:通常情况下答案是否定的,这时首先要做的是转移到其他地方开始处理中断。在存储地址的情况下,CPU会直接将其加载到程序计数器中。
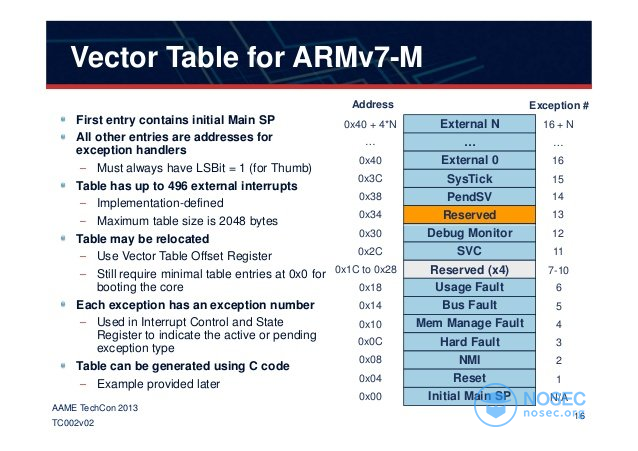
中断向量表
这个指针表,也称为中断向量表(IVT),通常存储在内存的最低址部分(例如,前n个位置,我们稍后会看到)。其中,表项都有对应的索引,它与中断中保存的索引的作用相同,用于实现快速查找。
中断与系统异常非常相似,其主要区别在于生成中断的组件:前者由特定于体系结构的外围模块生成,而后者由CPU生成;它们也是不可预测的,而异常是确定性的,是对某些程序行为的响应。
在操作系统中,由内核来处理中断,但在裸机二进制文件中,如U-Boot,单个二进制文件应该自己保存并处理IVT。因此,在分析原始二进制文件时,IVT是一个很好的起点。在我们的具体例子中(对应于ARM设备),我们知道IVT应该被放置(它可以被重新定位)在地址空间的开始位置:0x00,0x04,0x08,……这意味着,只要找到IVT,我们就找到了该二进制代码的起始地址!
下面是中断向量表的图示:
 在
在
GitHub上搜索了一段时间后,我们发现了一些代码,这些代码证实了我们所分析的特定SoC/板的中断向量表的结构。它与前一个略有不同,因为它遵循一些ARM SoC专有的特性。
.globl _start
_start: b reset
ldr pc,_undefined_instruction
ldr pc,_software_interrupt
ldr pc,_prefetch_abort
ldr pc,_data_abort
ldr pc,_not_used
ldr pc,_irq
ldr pc,_fiq
_undefined_instruction: .wordundefined_instruction
_software_interrupt: .word software_interrupt
_prefetch_abort: .word prefetch_abort
_data_abort: .word data_abort
_not_used: .wordnot_used
_irq: .wordirq
_fiq: .wordfiq
_pad: .word0x12345678 /* now 16*4=64 */
当处理器复位时,硬件会将pc设置为0x0000,并通过获取0x0000处的指令开始执行。当执行或试图执行未定义的指令时,硬件响应会将pc设置为0x0004,并在0x0004处开始执行该指令。发生irq中断时,硬件会完成正在执行的指令,然后跳转到0x0018地址,并执行该地址处的指令。——摘自stackoverflow
要想深入了解IVT、中断和异常处理,以及ARM CPU引导过程,请查看后面的参考资料部分!
唤醒三头龙
Ghidra的配置

接下来,我们将通过Ghidra来逆向分析我们的U-Boot二进制文件。
当我们在Ghidra中导入U-Boot时,Ghidra会把它作为一个原始二进制文件来加载,我们应该指定该二进制代码所对应的CPU架构。幸运的是,我们从数据手册中得知,该SoC是由两个ARM-ACPU组成的。在搜索引擎上快速搜索ARM-A17,发现该处理器是基于ARMv7-EL架构的。
我们可以用找到的信息来配置加载器。
手动分析
实际上,Ghidra非常聪明,甚至在深入分析之前就识别出了IVT。
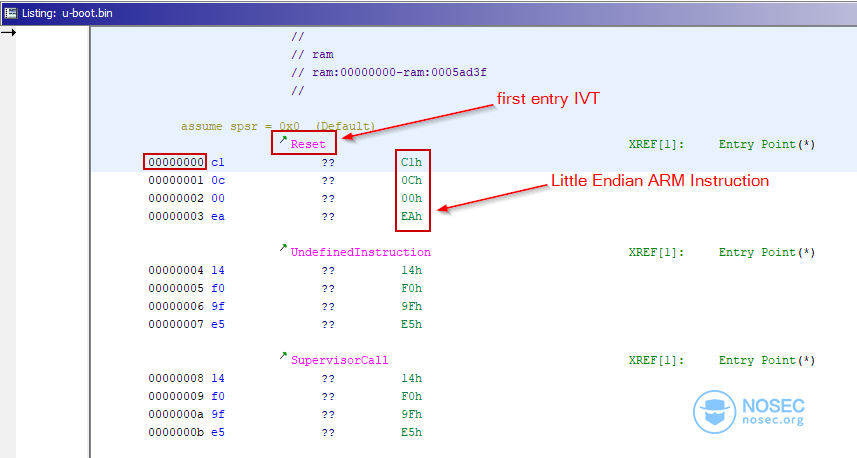
其中,高亮显示的、长度为DWORD的十六进制序列是一条无条件的ARM指令。
从统计上看,无条件指令是最常见的指令,它们可以通过第一个比特位进行识别,这些指令对应于0xE0-0xEF范围内(请记住,该体系结构是little-endian的,因此,最高有效位就是最后一位)。
关于指令的长度,我想说一点题外话。
Arm架构支持三种指令集:A64、A32和T32。
A64和A32指令集的固定指令长度为32位。T32指令集是作为16位指令集的一个补充集推出的,用于改进用户代码的代码密度。随着时间的推移,T32演变成一个16位和32位的混合长度指令集。因此,编译器可以通过单个指令集来平衡性能和代码长度。
——摘自:https://developer.arm.com/architectures/instruction-sets
两条等价指令之间的区别在于执行前如何取指和解释,而不是它们的功能。由于从16位到32位指令的扩展是通过芯片内的专用硬件完成的,因此,并不会降低执行速度。然而,16位指令能够节约更多的内存空间。现在,假设在我们的案例中,CPU使用的是ARM的“ARM”(而不是ARM的Thumb)指令,也就是说,我们使用的指令的长度为32位。请记住,CPU可以在运行时切换到Thumb模式,也可以从Thumb模式中切换回来。
让我们把指令转换成它的二进制表示。
ea -> 11101010
00 -> 00000000
0c -> 00001100
c1 -> 11000001
ARM分支指令的结构如下所示:
- 第31-28位:条件
- 第27-25位:固定序列
- 第24位:链接位(linkbit)
- 第23-0位:偏移量,用二进制补码表示

这条ARM指令是一个分支指令(在ASM代码中用B表示),其功能是(如果满足一个条件)跳到一个地址(PC+偏移量)处,从而改变执行流程。
前4位是1110,对应于 “忽略所有CPU标志”,因此又称无条件分支。
接下来的3位在分支指令中被固定为101。
第7位表示分支是否应该存储一个返回的链接。如果它被设置为1,那么一个地址将被存储在R14寄存器中,当函数执行完成后,CPU将跳回该地址。在我们的例子中,该位被设置为0,所以,它只是分支,而不存储任何东西到R14寄存器。
最后几位存储了一个24位的补码。出于内存对齐的目的,它被左移2位,带符号扩展为32位,并与PC+8相加,得到要跳转的内存地址。
使用Ghidra的反编译器,我们可以对第一个DWORD进行反编译,结果发现每条指令都对应着一个不同的中断。
除了第一个中断(“复位”)外,所有其他的中断都是通过LDR汇编指令在PC内部以偏移方式进行加载——我们对此特别感兴趣,因为我们知道RAM的起始位置(0x8000_0000),但不知道二进制文件的偏移量。
Ghidra默认在地址0x0处加载原始二进制文件,但我们注意到,引用被突出显示为红色,因为它们指向二进制内存区域之外。我们通过U-Boot实际被加载的位置推断出,这里的偏移量是0x0080_0000。
zi0black:我必须感谢@blessthe28,他帮我捋清了裸机二进制内的IVT结构。
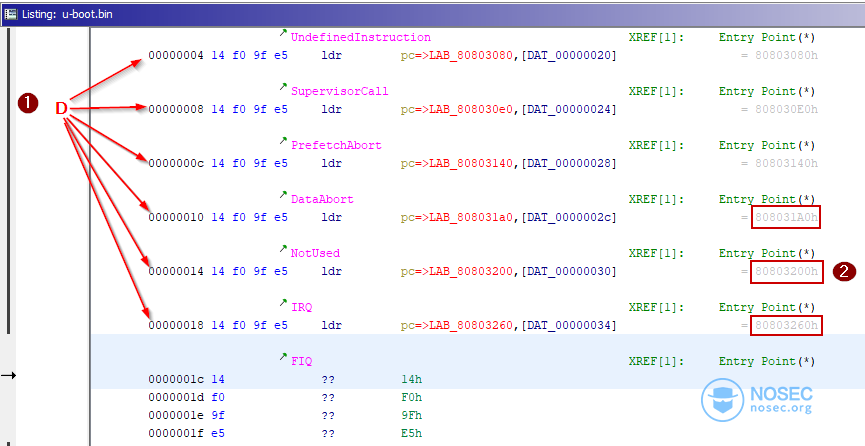
最后,我们可以在Ghidra内部重新定位二进制代码所在内存块,并添加缺少的内存块(即RAM),这使得Ghidra能够更好地分析二进制文件。
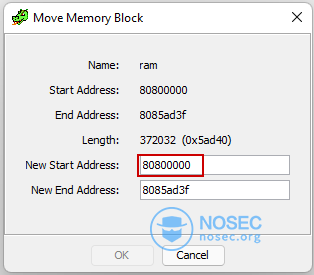
正确配置内存块后,Ghidra就能正确地识别出所有引用了!
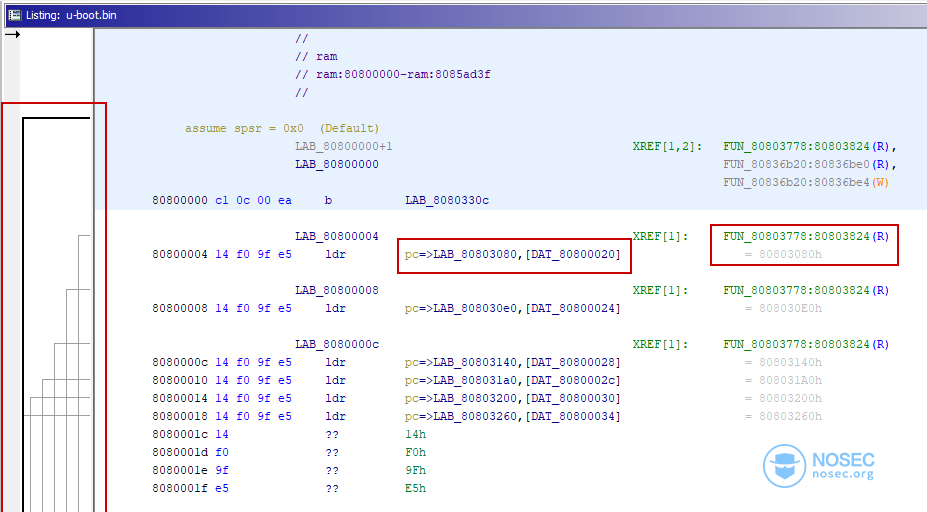
我们现在可以通过搜索ARM指令来启动Ghidra的自动分析。
注意:有时,激进的指令查找器会将某些数据块定义为代码,所以,这一点要多加注意!
利用开源代码
因为我们有一个U-Boot的自定义实现,所以,我们选择做两件事:
- 定义通用函数(它是一个静态二进制文件,不依赖于任何libC)。
- 导入U-Boot头文件并创建自定义DataTypes库。
因此,我们开始阅读DAS-U-boot的源代码,并很快确定了memcpy、memcp和printf等函数的导出位置,然后在被逆向的二进制文件中搜索它们的踪迹。
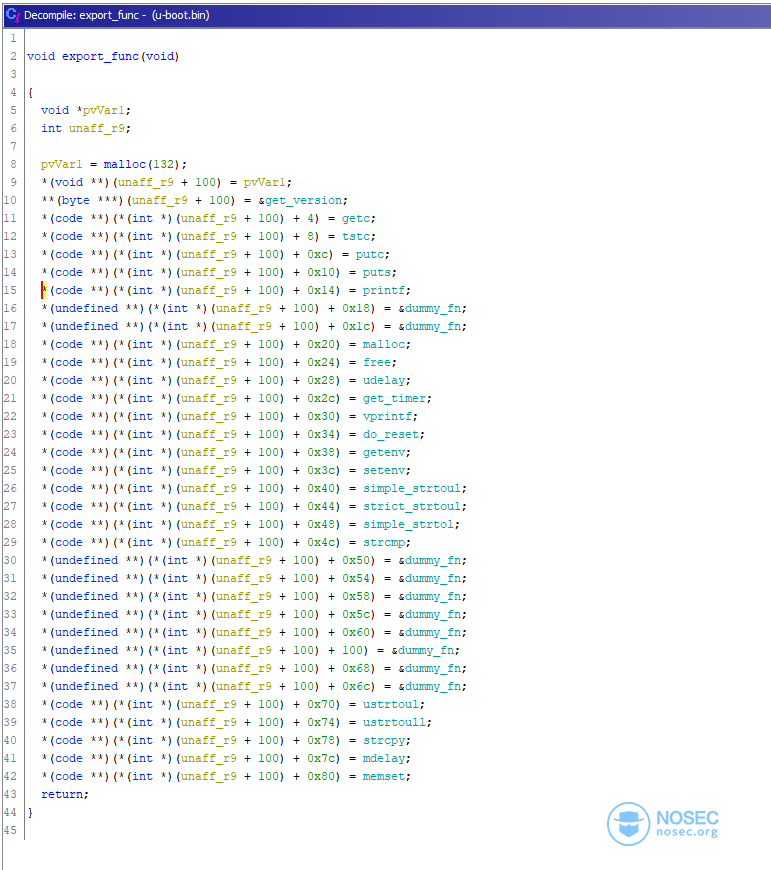
同时,我们也开始构建自定义DataTypes库。
Ghidra在导入头文件方面提供了很好的支持,并能够自动解析导入的代码。如果选择只导入几个头文件,有时可能需要修改导入顺序。这个过程远难以实现自动化,所以,有时需要手动方式处理头文件。
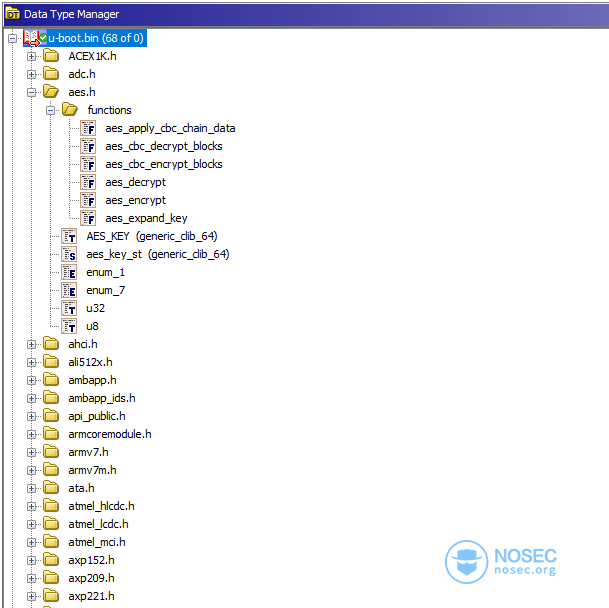
我们终于借助Ghidra创建了一个易于“翻阅”的项目,接下来,我们开始考察加密函数!
谁不喜欢逆向加密算法?我们!
现在,我们已经掌握了引导过程的具体步骤:
- 加载并执行自定义的U-Boot BootLoader。
- U-Boot将经过加密处理的Linux内核加载到内存中。
- U-Boot对一些硬编码数据执行密钥派生函数(请记住,该设备不使用ARM Trust Zone)。
- 在内存中对内核代码进行解密。
- BootLoader运行内核代码。
- 内核可能需要解密rootfs,因为BootLoader没有实现这样的功能。
我们仍然不知道解密机制是如何实现的,因为它是自定义的,并且不存在于U-Boot源代码中,所以,我们开始在代码中搜索常见的密码常量,以识别所使用的密码算法。
基本上,大多数密码算法都会用到一些常量,用于执行各种类型的操作,例如初始化向量、种子、S盒等。
当密码算法通过编程语言实现时,这些常量会作为数据嵌入程序中,并编译成二进制文件(就我们的例子而言)。因此,可以搜索这些常量出现的位置,跟踪使用它们的函数,并识别发生了什么,使用了哪些算法,即使二进制代码中的符号被删除了。
为了完成这个任务,我们可以使用ghidra-findcrypt(https://github.com/TorgoTorgo/ghidra-findcrypt)来处理BootLoader的二进制文件。
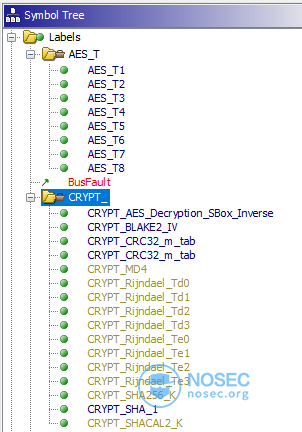
注意:ghidra-findcrypt检测到一个BLAKE2 IV,但这是一个误报,因为BLAKE2bIV与SHA-512 IV相同,而BLAKE2s IV与SHA-256 IV相同。

例如,在上图中,我们可以看到经过一些变量重命名和类型定义之后的AES解密函数。现在代码比以前更易读了,我们可以将其与标准的AES解密函数进行比较,看看它们的功能是否相同。事实上,它们是一样的。
所以我们现在知道,AES是用来解密数据的,而SHA1是用来生成密钥的。我们最初的想法是获得加密密钥和函数参数,然后写一个方便的python脚本来解密内核。

不幸的是,事实证明它使用了一种奇怪的操作模式。
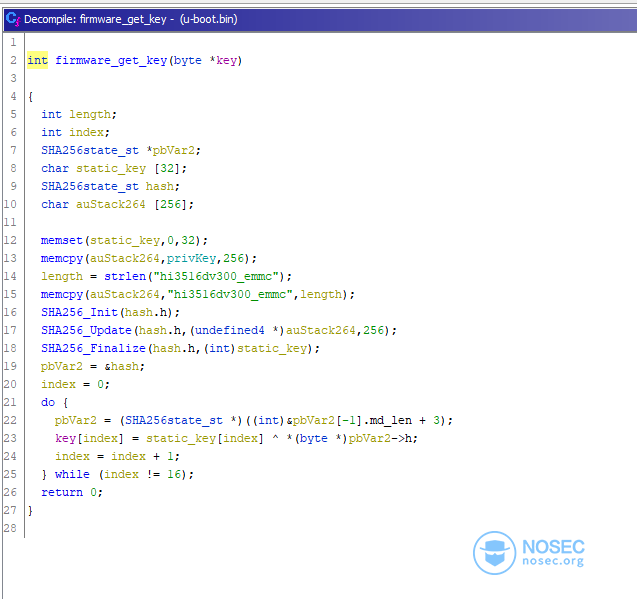 注意:
注意:
上图仅显示了解密过程和密钥派生所涉及的多个函数中的一个。
现在,我们有两个选择:
- 忽略令人头疼的问题,继续逆向密码算法,并重新实现它。
- 发挥创造能力!
正如你可能猜到的,我们怕麻烦,更喜欢创造性!
在下一篇文章中,我们将解释如何通过逆向工程过程收集的信息来模拟U-Boot并解密内核!
更多精彩内容,敬请关注!
zi0black:特别感谢“AGuide to Kernel Exploitation”的作者Enrico'Twiz'Perla审阅本文以及一直以来的帮助和善意。
参考资料
- http://classweb.ece.umd.edu/enee447.S2016/ARM-Documentation/ARM-Interrupts-3.pdf
- https://www.design-reuse.com/articles/38128/method-for-booting-arm-ba sed-multi-core-socs.html
- https://stackoverflow.com/questions/6139952/what-is-the-booting-process-for-arm
- https://iitd-plos.github.io/col718/ref/arm-instructionset.pdf
- https://interrupt.memfault.com/blog/how-to-write-linker-sc ripts-for-firmware
- https://www.vinnie.work/docs/embeddedsystemsanalysis/firmware/bareme talbinary/
- https://www.coranac.com/tonc/text/asm.htm
- https://azeria-labs.com/writing-arm-assembly-part-1/
原文地址:https://www.shielder.it/blog/2022/03/reversing-embedded-device-bootloader-u-boot-p.1/



最新评论