我是如何绕过麻省理工文献网站的阅读限制的
 iso60001 2703天前
iso60001 2703天前
在本文中,我将展示如何利用网站设计中的漏洞在麻省理工的付费技术分享网站中畅行无阻。
很久以前,我就喜欢在www.technologyreview.com网站上阅读科学文章。但是,对于普通访客来说,每月只能阅读三篇文章。只有订阅付费才能阅读全部的文章。
每当我阅读一篇文章,就会出现一个提示,告诉我已经阅读了这个月内几篇免费文章。在我读完3篇文章后,它就提示我订阅付费以继续阅读。

于是,我开始思考这个限制功能是如何运行的,以及如何绕过它。也许可以通过创建大量帐户(或不断更改IP地址),每个帐户阅读三篇文章后更换帐号来解决,但我不认为这是一个合理的方案。
最初,我猜测,每次我点击一个文章URL,浏览器都会向服务器发出一个请求,检查我一个月内阅读的文章数量是否少于3篇,后端服务器会保留我阅读过的文章ID(以便我可以重新阅读文章),最后,我会从服务器得到相应的响应(直接看文章或者提示我需要付费订阅)。
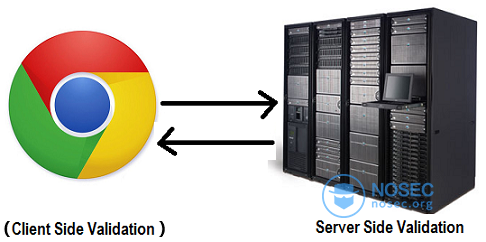
以上猜测似乎很合乎逻辑,但我决定还是在网页源码找找线索。很快,我就发现很有趣的和“逆向工程”有关的代码。
- 首先,我发现了下面的HTML代码,这些代码会显示我已阅读了几篇文章:
<!-- Reading Meter -->
<di v class="meter">
<span show="meter.loggedIn.1">
<span class="meter__line"> You've read
<span text="meter.usageWord"></span> of three free articles this month.
</span>
- 然后,我在源码中搜索单词“meter”,因为它貌似是一个重要的字符串。于是我找到了一个脚本,它会把一个JSON类型数据分配给一个名为“serverData”的变量。以下是脚本的一部分:
<sc ript> serverData = "user":{"id":1111111,"username":"John D","email":"myemail@gmail.com","status":"active","rss_token":"st45pew5rX2UQmFafadsgajtP92a","livefyre_id":"uid_11111111","notifications_unread":0,"profile":{"status":"public","display_name_from":"username","name":"John D","url":"/profile/john-d/","first_name":"John","last_name":"D"},"meter":{"month":"2018-01","count":1,"ids":[600000],"hits":[{"id":600000,"date":"2018-01-01T15:11:32-04:00"}]},"email_notifications":....
</sc ript>
- 接着,还有一些指向其他前端脚本的链接,我也打开了查看:
<sc ript src="https://cdn.technologyreview.com/js/example.js?v=22222222" defer></sc ript>
- 通过搜索,我在大量代码发现了一些重要信息:
function P(e,t){e.func.call(e.context,t,e.count++)}
function w(){if(!y())return!1;o.meter={usage:i.length>h.allowed?h.allowed:i.length,allowed:h.allowed,allowedMax:h.allowedMax,...,loggedIn:{1:!1,2:!1,3:!1,"3b":!1},loggedOut:{"1a":!1,"1b":!1}},o.meter.loggedIn[o.meter.usage.toString()]=!0,null==e&&(b=11==(S=new Date).getMonth()...t(window).trigger("mittr:meterBlock",[{reason:"User is above the allowed view limit",...{if(o.meter={usage:e.ids.length>h.allowed?h.allowed:e.ids.length,allowed:h.allowed,allowedMax:h.allowedMax,visible:!0,open:!0,paywall:!1,usageWord:"",allowedWord:"",loggedIn:{1:!1,2:!1,3:!1,"3b":!1},....loggedOut:e.ids.length+1>o.meter.allowedMax?]}
OK,阅读文章计数器的增加和检查都是在前端用脚本完成的!!(甚至你都不需要登录)
现在,如果我要阅读更多的文章,仅仅只要现在阻止这段前端脚本代码运行就可以了!

在发现了这个问题后,我还是抵制住了诱惑,向麻省理工发送了一封电子邮件,报告了这个漏洞。
综上所述,这个网站存在两个问题:
a)用户在一个月内的阅读文章数的检查是在客户端进行的,禁用JS,用户就可以无限制阅读文章。
b)阅读文章计数器的递增也是在前端。因此,即使在服务器端进行文章数目的验证,我们仍然可以通过控制计数器来无限制访问文章。
此外,我还发现,如果删除cookie,就无法访问与用户相关的数据。因此,绕过订阅付费的另一种方法是篡改cookie。
有人可能认为这种脆弱性并不严重,但在我看来,这并不完全正确。
结论
首先,这看似是一个小错误,但它反映出这个网站的设计思路有问题,可能我们能在前端脚本中发现更多敏感信息。网站服务的前后端都需要安全检查。
另外,这个漏洞可以让攻击者偷取所有的网站文章,然后进行二次售卖。这可能牵涉到巨大的经济利益,同时也会影响原网站的收入。
后续:
在写完这篇文章之后,我也检查了很多其他的网站,他们的订阅付费可以用同样的方法绕过。此外,在某些情况下,您可以浏览器打开添加某些阻塞代码,这在以前是不可能的。
到目前为止,我发现存在问题的网站有:
MIT Technology Review,
Business Insider,
The New York Times,(纽约时报)
The Washington Post,(华盛顿邮报)
The Economist,(经济学家)
The Boston Globe
感谢你的阅读!
本文由白帽汇整理并翻译,不代表白帽汇任何观点和立场
来源:https://hackernoon.com/how-i-hacked-the-mit-technology-review-website-many-more-and-gained-unlimited-online-access-e89a57cdc248


 评论正在提交,请稍等...
评论正在提交,请稍等...

最新评论