regulator :一种独特的子域枚举方法
 xiannv 1382天前
xiannv 1382天前目录
介绍
显而易见的是:子域枚举是我们希望为一组特定的根域查找子域的地方。子域枚举只是大型侦测过程的一小部分,该过程通常是渗透测试或 Red Team 的第一阶段。
子域枚举有很多不同的方法,但我想向您展示一种独特的方法,我几乎可以保证您以前从未见过。
在之前的一篇博客文章中,我介绍并展示了如何使用它独特的编码机制来编码用于注入和加载程序的shellcode。
在这篇文章中,我将探讨另一个用例,我们如何将常规语言排名的概念与常规语言归纳相结合。dank
我们的目标是能够自动学习正则表达式,以捕获观察到的DNS数据的特殊特征。使用这些学习的模式,我们将尝试对遵循这些相同模式的新子域进行暴力破解。
我将通过实验证明,与其他行业知名工具(如.altdns)相比,这种方法似乎非常有效。
我称这个项目为“regulator”,你可以在我的GitHub上找到它 这里
注意:这里有相当多的挥手和“it just works”的心态,尽管我会尽力解释为什么它会随着我们的前进而起作用,但实际上,我没有一个正式的技术性答案。
TL;DR
我们使用现有工具收集尽可能多的 DNS 数据:
amasssubfinder等。我们从这些观察到的DNS数据中归纳出常规语言
我们使用这些语言(正则表达式)来合成新的DNS主机名
我们使用类似的工具评估结果,例如:
altdnsdnsgen
收集初始数据
此过程严重依赖于初始输入数据,因此您应该花一些时间确保您已经从现有的工具/方法中获取了所有可能的信息。
还值得指出的是,此过程不适用于小域(即少于约100个子域),因为字典爆破等其他工具通常有更好的效果。
诱导语言
该过程很复杂,最好通过阅读上面链接的代码来总结。简单地说,关键函数为:closure_to_regex
def closure_to_regex(domain: str, members: List[str]) -> str:
"""converts edit closure to a regular language"""
ret, levels, optional = '', {}, {}
tokens = tokenize(members)
for member in tokens:
for i, level in enumerate(member):
if i not in levels:
levels[i] = {}
optional[i] = {}
for j, token in enumerate(level):
if not j in levels[i]:
levels[i][j] = set([])
optional[i][j] = []
levels[i][j].add(token)
optional[i][j].append(token)
for i, level in enumerate(levels):
n = '(.' if i != 0 else ''
for j, position in enumerate(levels[level]):
k = len(levels[level][position])
# Special case: first token in DNS name
if i == 0 and j == 0:
n += f"({'|'.join(levels[level][position])})"
# Special case: single element in alternation at start of level
elif k == 1 and j == 0:
# TODO: Should we make this optional too?
n += f"{'|'.join(levels[level][position])}"
# General case
else:
# A position is optional if some token doesn't have that position
isoptional = len(optional[level][position]) != len(members)
n += f"({'|'.join(levels[level][position])}){'?' if isoptional else ''}"
# A level is optional if either not every host has the level, or if there
# are distinct level values
values = list(map(lambda x: ''.join(x), zip(*optional[level].values())))
isoptional = len(set(values)) != 1 or len(values) != len(members)
ret += (n + ")?" if isoptional else n + ")") if i != 0 else n
return compress_number_ranges(f'{ret}.{domain}')
如果你对语言归纳法有所了解,你可能会非常困惑。那是因为我上面展示的不是一种诱导常规语言(如L-star或RPNI)的正式方法,而是一个简单的启发式函数。
不过,这似乎很有效,因为我们正在处理的数据很简单,并且通常是高度结构化的。以下是上述函数的作用:
假设您有:
foo1-dev.example.comfoo2-prod.example.comfoo5-qa.example.com
该函数将这些实例标记化为:
[foo1, dev, example, com][foo2, prod, example, com][foo5, qa, example, com]
然后,它将它们重新组合成模式或“规则”,其中共性的“级别”被合并:
(foo1|foo2|foo5)-(dev|qa|prod).example.com最后,它分析数值并将其转换为范围(如果可以的话):
(foo[1-5])-(dev|qa|prod).example.com
查看获得的最终规则,我们可以看到,有一些以前未观察到的新名称是我们推断的常规语言的一部分:
foo1-qa.example.comfoo2-dev.example.comfoo3-prod.example.com- ...
正是这些新的语言成员构成了我们的暴力尝试。关于我们在这里所做的工作,还有很多可以说的,但我不想过多地讨论这个问题,因为这篇文章放不下太多的信息。
合成新名称
从我们的正则表达式规则生成新名称的过程,就是枚举所有语言成员,并根据我们已经观察到的内容进行重复数据删除的过程。
第一部分可以使用包中的类来完成,后一部分使用集合差异来完成。
>>> from dank.DankGenerator import DankGenerator
>>> for i in DankGenerator('(foo[1-5])-(dev|qa|prod).example.com'):
... print(i)
...
b'foo5-qa.example.com'
b'foo4-qa.example.com'
b'foo3-qa.example.com'
b'foo2-qa.example.com'
b'foo1-qa.example.com'
b'foo5-dev.example.com'
b'foo4-dev.example.com'
b'foo3-dev.example.com'
b'foo2-dev.example.com'
b'foo1-dev.example.com'
b'foo5-prod.example.com'
b'foo4-prod.example.com'
b'foo3-prod.example.com'
b'foo2-prod.example.com'
b'foo1-prod.example.com'
在开发regulator 时,显而易见的一件事是,我们需要某种过滤标准来过滤我们的规则。基本上,一些规则会产生天文数字的语言成员数量,我们不希望我们执行的猜测数量远远超过1,000,000。因此,我们需要一种方法来过滤掉某些规则。
我决定的是一个简单的比率测试。其逻辑是,观察到的语言成员的数量不应超过某个整数倍,默认值为25。这意味着,如果我们观察 10 个主机来生成一个规则,那么该规则在被过滤之前最多可以包含 250 个语言成员——这似乎在捕获“正确猜测”而不扩大猜测总数方面非常有效。
一个真实的例子:adobe.com
数据采集
我使用标志收集了初始数据。这需要一段时间,但在完成之后,我们有了主机。amass-brute1960
我们可以运行调节器脚本来生成此输入的规则:
python3.8 main.py adobe.com adobe adobe.rules
诱导语言
您可以查看其中存储的日志文件,以查看进度:logs/
2022-10-16 12:16:30,702 - root - INFO - REGULATOR starting: MAX_RATIO=25.0, THRESHOLD=500
2022-10-16 12:16:30,706 - root - INFO - Loaded 1960 observations
2022-10-16 12:16:30,706 - root - INFO - Building table of all pairwise distances...
2022-10-16 12:16:34,594 - root - INFO - Table building complete
2022-10-16 12:16:34,594 - root - INFO - k=2
2022-10-16 12:16:36,733 - root - INFO - k=3
2022-10-16 12:16:38,761 - root - INFO - k=4
2022-10-16 12:16:41,900 - root - INFO - k=5
正在构建的记忆表是一个表,其中包含1960年所有观测数据之间的成对Levenshtein distances。
这个常见的字符串度量用于定义“Levenshtein closure”的概念 - 这就是“closure”的含义:一组以某个固定的 Levenshtein distances 为界的主机名。closure_to_regex
记忆完成后,我们可以看到该工具的更多输出:
2022-10-16 12:17:34,865 - root - INFO - Prefix=armmf
2022-10-16 12:17:34,866 - root - INFO - Prefix=armmfsso
2022-10-16 12:17:34,867 - root - INFO - Prefix=artifactory
2022-10-16 12:17:34,889 - root - INFO - Prefix=asa
2022-10-16 12:17:34,931 - root - ERROR - Rule cannot be processed: (asa)(-noida|-paris|-sjspa|-lehi|-orem|-test|-tokyo|-sngeqx)((-[1-4])|(-ext|-c))(2|-ext|-c)?([1-2])?.adobe.com
我们使用前缀树(也称为 Trie)来计算主机名的通用前缀,这些前缀用于帮助制定我们最终创建的规则。
产生的错误是预期的,这只是当特定规则未通过上述比率测试时生成的错误。请注意,有多个尝试将给定的闭包转换为规则,因此,仅仅因为此特定尝试失败并不意味着数据将不会被使用。
脚本完成后,我们可以看到生成的规则:
$ wc -l adobe.rules
6215 adobe.rules
$ head adobe.rules
(genuine|muse|indd|dev|guided|udps|geo|edex|kuler|voice|line|gd|lime|gcoe|view|ideas).adobe.com
(flashlitedemo).adobe.com
(awc).adobe.com
(learning|learnearnwin|learn)(-origin)?(-du|-da)?(1)?(.wip(4)?)?.adobe.com
(research|access|rome|resources|resellers|readerscert|remotetraffic|remoteaccess|readiness)(-test|1)?.adobe.com
(res)(4)(.service)(.tele(2))(.se)(.cname)(.campaign).adobe.com
(messenger).adobe.com
(press|express).adobe.com
(av)(-beta|-sjc)(0)?.adobe.com
(www)(.stock).adobe.com
其中一些可能看起来很蠢(也许真的很蠢?),但我们很快就会检查结果,看看它们的表现如何。
生成暴力破解列表
现在我们有了规则,我们需要生成我们的暴力破解列表,我们只需运行其中的脚本:make_brute_list.sh
$ ./make_brute_list.sh adobe.rules adobe.brute
$ wc -l adobe.brute
124821 adobe.brute
$ head adobe.brute
19-da-tryit.adobe.com
19-da-tryit1.adobe.com
19-da-tryit2.adobe.com
19-da-vip.adobe.com
19-da-vip1.adobe.com
19-da-vip2.adobe.com
19-da1.adobe.com
19-da11.adobe.com
19-da12.adobe.com
19-origin-tryit.adobe.com
评价altdns
我认为该工具(https://github.com/infosec-au/altdns)是一个恰当的比较。这两种工具都有类似的目的:给定一些输入DNS名称,两者都生成突变名称作为输出,以便在DNS暴力破解中使用。altdns
以下是我如何生成列表(其中与上面使用的输出相同):altdnsadobeamass
$ python3 altdns/altdns -i f500/adobe -o adobe_altdns -w altdns/words.txt
$ wc -l adobe_altdns
3619334
以下是我用来比较的非科学方法:
使用 DigitalOcean VPS
使用(https://github.com/vortexau/dnsvalidator)工具收集有效的公共 DNS 解析程序
dnsvalidator将(https://github.com/d3mondev/puredns)工具与 [2] 中的公共解析器配合使用以进行 DNS 解析
puredns将结果与我们最初收集到的结果进行对比,删除重复结果
amass重新收集解析器,并在运行之间等待 30 分钟
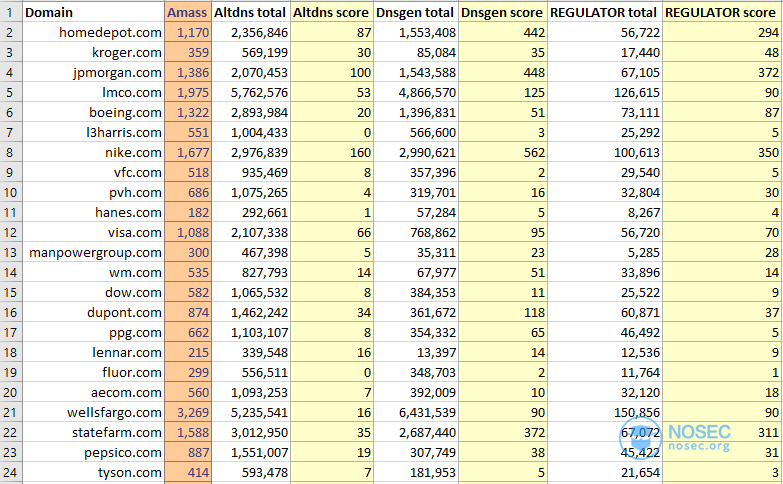
结果
以下是我获得的结果:
- 对于猜测,regulator 捕获了新的主机名
124,8211242 - 对于猜测,捕获
3,619,334altdns362
我不打算过多地解释结果,但我认为,公平地说,regulator 以绝对数字“赢得”了这一轮。
结论
我已经附加了我在regulator 和(https://github.com/ProjectAnte/dnsgen)之间收集的更多试验。altdnsdnsgen
regulator 似乎确实相当“高效”,这取决于你想要的计数方式,但它仍然在一般情况下输了(我也用了标志)。dnsgen--fastdnsgen
总的来说,我对这个项目的结果很满意,我学习到了一些很酷的东西,并希望激励其他人使用。dank
原文:Regulator: A unique method of subdomain enumeration (cramppet.github.io)



最新评论