模糊测试与CVE-2021-26236漏洞的故事
 匿名者 1943天前
匿名者 1943天前简介
在之前的文章中,我已经从理论的角度对模糊测试技术进行了相应的介绍。正如我之前所承诺的那样,现在将披露本人在发掘FastStone Image Viewer v.<=7.5中5个不同漏洞过程中,具体使用的模糊测试方法、测试过程和测试样本。同时,我还会为读者介绍导致CVE-2021-26236漏洞的根本原因,以及如何利用该漏洞来实现任意代码执行。
文件格式模糊测试技术
尽管文件格式模糊测试的概念和工作流程很容易理解:向fuzzer提供一个正常的文件样本(基线),再由fuzzer对其进行突变处理,从而得到新的测试用例,并在打开这些测试用例时考察目标应用程序是否发生崩溃或挂起现象;但是,文件格式模糊测试技术也带来了测试方法论方面的新挑战和实际问题。例如,我们如何监控目标进程以识别崩溃状况,并提取有意义的数据,以用于崩溃的分类和漏洞利用阶段?
首先,我们来考察一下使用早先的PeachFuzzer框架的自动化测试方法。
和网络模糊测试一样(它们都涉及复杂的协议),文件格式模糊测试也有很多测试重用的机会。例如,如果我们编写了一个JPG文件fuzzer,那么,我们还能够用它来测试各种处理图像文件、原生Windows二进制文件和常见的开源库的应用程序。
实际上,标准文件格式与专有文件格式(或协议)都有各自的优缺点:
- 标准文件或协议通常是很有吸引力的,因为它们为重用生成的测试用例提供了多种机会。
- 标准文件或协议harness更易于创建,因为已经存在许多相关的文档;对于专有的文件或协议来说,则需要巨大的前期时间成本,来进行harness的开发和逆向工程。
- 另一方面,专有文件或协议可能非常复杂,难以理解,但这也意味着研究它们的人相对较少,从而使得它们成为一个完美的、漏洞丰富的攻击面。
目标程序:FastStone Image Viewer
当讨论模糊测试时,我最常被问到的一个问题是:“如何选择好的目标程序呢?”。实际上,在我看来,目标程序只是测试对象而已,并没有什么好坏之分。即使是非常常见的、经过充分的模糊测试的程序,也会不断曝出各种安全漏洞(想想Google Chrome就知道了);当然,其中一些程序会比其他的更易于进行模糊测试,或者更易于利用。
经过一番综合考虑,我决定考察一个专有软件,即FastStoneImage Viewer,具体原因如下所示:
- 它是一个专有软件,因此,肯定少不了逆向分析环节(对于逆向分析,必须经常练手,否则就会手生);同时,这也意味着对其进行模糊测试的人相对较少,因为逆向分析是非常耗时间的。
- 该软件曾经曝出过一些漏洞,其中大部分都是内存损坏所致。
- FastStone Image Viewer可以处理多种文件格式(这就意味着多种文件扩展名),因此,可以提供更大的攻击面。格式解析器越多,出错的机率越大。
- 它是Ninite上列出的图像查看器应用程序之一,这意味着它在许多系统中,它将作为一个捆绑应用程序进行安装。另外,该软件还经常更新,同时,它的下载量较大:仅在Cnet网站上,其下载量就达到13,885,983次,这还不包括其他镜像或软件供应商网站上的下载量。
CNET网站上的统计数据:
- 最后更新于03/19/20
- 总下载量13,885,983次
CUR文件格式
在进行针对文件格式的模糊测试时,我通常的做法,是先了解一下要处理的文件格式;之所以这样做,不仅因为它本身就很有意思,同时,在遇到代码崩溃的时候,如果前期已经花了时间来学习相应的格式规范,以了解这些格式的工作原理以及文件中哪些地方容易出现漏洞的话,那么在漏洞利用阶段,这些知识就能帮我们节约不少时间。
FastStone Image Viewer能够处理多种文件格式,例如BMP、CUR、GIF、ICO、JPEG等。
其中,我选择的是CUR文件格式,原因如下:首先,与PNG或JPG文件格式相比,它更容易理解;其次,从影响FastStone Image Viewer的CVE历史来看,还没有人关注过CUR格式,因为大多数常见的扩展名(JPG/PNG)才是安全研究人员的首选。
在处理文件格式或协议时,我总是使用010Editor,因为它不仅为最知名和最常用的文件格式提供了相应的模板,同时,还可以很容易地为未知/专有文件格式提供原型和草图模板。
不幸的是,虽然CUR文件是非常常见的一种格式,但是010 Editor并没有单独为它们提供相应的模板,因此,我只好自己动手开发了一个模板(和本文的其他所有代码片段一样,该模版也可以从本人的GitHub存储库中找到)。
当然,这里不会详细介绍010 Editor模板的工作原理,也不会介绍如何构建模板,如果有机会的话,我们将会专文加以解释。
CUR文件格式用于微软Windows系统中的非动画光标。值得注意的是,这种格式与ICO图像文件格式几乎是完全相同的。这两种格式的主要区别在于标识它们的字节(魔术字节/签名),同时,在CUR格式头部中还多了一个“hotspot”字段。这个字段被定义为用户实际指向鼠标的光标图像左上角的像素偏移量(以x,y为坐标)。
实际上,网上可以找到Cur文件格式规范的参考资料,有了它们,我们就可以开始构建自己的模板了。这对我们的帮助很大,因为我们不仅可以自由探索数据结构,而且还可以在需要时突出显示感兴趣的信息。
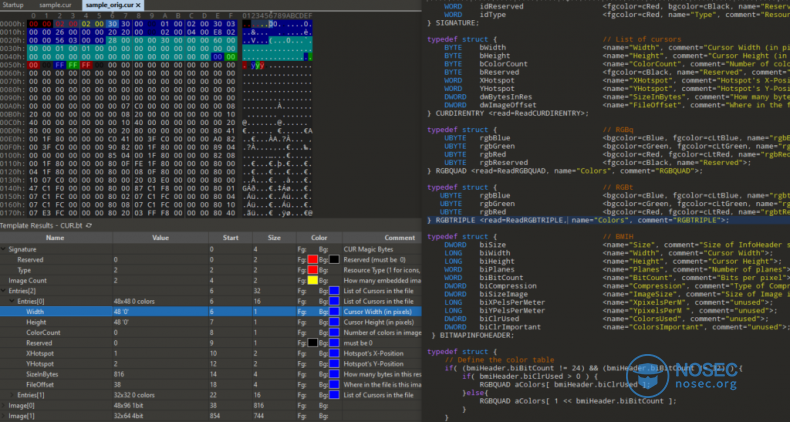
CUR文件格式模板
有趣的是,CUR图片如果没有经过压缩的话,也可以用原始字节进行查看。
光标文件的原始字节视图
Peach框架
尽管Peach是一个古老的fuzzer,而且Windows操作系统是模糊测试的最大瓶颈(因为它无法支持持久型/存内模糊测试,因为它没有提供fork()函数),但是作为一款入门级别的fuzzer来说,Peach仍然是不二之选。
我们可以用两种方式来使用Peach:
- 傻瓜方式:我们给Peach提供一个基线文件,该文件将不断发生突变。
- 聪明方式:我们为Peach提供一个“pit”文件,用于描述需要进行突变处理的文件的格式/结构。
在这两种情况下,Peach都会执行下列操作:
- 打开目标应用程序。
- 令文件发生突变。
- 加载发生突变后的文件。
- 等待,看看是否会触发应用程序的崩溃。
- 在预定的时间后或当崩溃发生时,终止应用程序并重新开始。
傻瓜方式
对于傻瓜方式,配置非常简单:
- 创建一个文件夹,让Peach生成测试用例(例如:C:\peach\samples)。
- 在上面的文件夹中加载任意光标文件,Peach就会令其发生突变,并提供给目标程序。
- 创建一个文件夹,Peach将在其中保存导致崩溃的测试用例(例如:C:\crashes)。
- 创建“pit”配置文件(cur_dumb.xml)。
<?xml version="1.0"encoding="utf-8"?>
<Peach xmlns="http://peachfuzzer.com/2012/Peach"xmlns:xsi="http://www.w3.org/2001/xmlSchema-instance"xsi:schemaLocation="http://peachfuzzer.com/2012/Peach../peach.xsd">
<DataModel name="TestTemplate">
<Blob/>
</DataModel>
<StateModelname="State" initialState="Initial">
<State name="Initial">
<Action type="output">
<DataModel ref="TestTemplate" />
<!-- Directory from where to load test cases to mutate -->
<Data name="data" fileName="C:\peach\samples/*.cur"/>
</Action>
<Action type="close" />
<Action type="call" method="LaunchViewer"publisher="Peach.Agent"/>
</State>
</StateModel>
<Agentname="WinAgent">
<Monitor class="WindowsDebugger">
<!-- Target process and command line to open "fuzzed" testcase -->
<Param name="CommandLine" value="C:\Program Files(x86)\FastStone Image Viewer\FSViewer.exe fuzz.cur" />
<!-- WinDbg folder -->
<Paramname="WinDbgPath" value="C:\Program Files (x86)\WindowsKits\10\Debuggers\x64\" />
<Param name="StartOnCall" value="LaunchViewer"/>
</Monitor>
<Monitor class="PageHeap">
<!-- Target process name -->
<Param name="Executable"value="FSViewer.exe"/>
<!-- WinDbg folder -->
<Param name="WinDbgPath" value="C:\Program Files(x86)\Windows Kits\10\Debuggers\x64\" />
</Monitor>
</Agent>
<Testname="Default">
<Agentref="WinAgent" platform="windows"/>
<StateModel ref="State"/>
<Publisher class="File">
<!--"Fuzzed" Test Case Name-->
<Paramname="FileName" value="fuzz.cur" />
</Publisher>
<Loggerclass="Filesystem">
<!-- Crashes Folder Location -->
<Param name="Path" value="C:\crashes\" />
</Logger>
</Test>
</Peach>
您可以通过打开cmd.exe(以管理员身份),并运行以下命令来测试您的Peach Pit文件是否已正确配置:
peach.exe -1 cur_dumb.xml
您应该能够看到目标应用程序加载示例CUR文件,然后立即关闭:
聪明方式(Pit文件)
在开始用聪明方式之前,我们先来详细介绍一下Peach的Pit文件组成方面的信息。对于下面的内容,主要引自Peach Fuzzing:Getting Started与Peach Fuzzer: Data Modelling这两篇文章:
- DataModel:它是用来定义我们的数据结构的。我们将使用DataModel为Peach提供CUR文件格式的数据结构布局。
- StateModel:它负责管理模糊测试过程中的数据流。
- Agent:用于监控目标应用在模糊测试过程中的行为,包括在可能触发的应用程序崩溃期间捕获有意义的数据。
- Test部分:它将StateModel、Agent和Publisher(发布方,负责管理DataModel生成的数据)的配置关联到一个测试用例中。
- Run部分:它定义了在模糊测试过程中将进行哪些测试。同时,它还负责管理代理生成的日志。
现在,让我们看看CUR文件规范,这样我们就可以定义自己的Pit文件了。通过下图我们可以看到,CUR文件由多个字段组成,并以“Reserved”、“Type”和“ImageCount”字段开头。接下来,是“Entry”部分,它充当其中存放的图像的“目录列表”,后面是一个“ImageCount”部分,该部分由“InfoHeader”和“ImageData”结构体组成。根据CUR文件规范,"Entry"部分和“Image”部分可以多次出现。

接下来,让我们把位于Path-to-Peach- installation\samples\FileFuzzerGui.xml中的FileFuzzerGui.xml模板复制一份,并保存为cur_smart.xml文件。实际上,这个模板已经定义了一个非常简单的DataModel,其作用是生成字符串“Hello World!”。之后,我们需要删除这个字符串,并将我们的DataModel重命名为 “Cur”,具体如下所示:
<DataModel name="Cur">
</DataModel>
在Peach中创建文件定义时,可以通过某些xml元素来定义要处理或生成的数据类型。
块参数
- Name:可用于创建具有唯一性的名称,以便在将来执行更多高级功能时引用这个名称。
- minOccurs:定义一个区块应该出现的最少次数。如果将minOccurs的值定义为0,则可以通知Peach这个块是可选的,也就是说,它可能根本不会出现。
- maxOccurs:该参数的作用于minOccurs很像,不过它定义了我们的区块出现的最大次数。
让我们先在DataModel中创建一个区块,来代表我们的“Reserved”、“Type”和“ImageCount”字段(这个区块必须至少出现一次)。
<DataModel name="Cur">
<Blockname="Signature" minOccurs="1" maxOccurs="1">
</Block>
</DataModel>
现在,我们已经创建了一个块来存放我们的字段,下面,让我们继续为Peach提供这部分的结构体。
基本元素
实际上,Peach主要使用4种元素来表示数据:
- String:这个元素通常用来表示文本或人类可读数据的字符串。在前面的FileFuzzerGui模板中,Peach曾经定义了一个字符串元素“Hello World!”。实际上,String元素是非常灵活的,甚至可以用来表示数字,但是,模糊测试过程中通常不会这样使用。
- Number:如您所料,这个元素也只用来表示数字数据。如果字段可能包含字母数字数据,那么使用String元素可能更为合适。
- Flags:这个元素用来表示位标志。它有一个子元素Flag,用于定义位标志中的每个位或位范围。
- Blob:当我们缺乏一个合适的定义时,通常用它来表示二进制数据。
我们开头部分的元素,即“Reserved”和“Type”字段,每个字段的长度为2个字节,它们其中的内容始终为一个十六进制值,即0x00000200。接下来,让我们在“Signature”块内为其创建一个定义。
即使这个元素可以很容易地表示为<Number>,但是在本文中,我们将使用<String>来演示它的用法。
<DataModel name="Cur">
<Blockname="Signature" minOccurs="1" maxOccurs="1">
<!--Reserved + Type (expressed in Little Endian Format) -->
<Stringname="CurSignature" value="0x00000200"valueType="hex" token="true" mutable="false"/>
<Numbername="ImageCount" size="16" endian="little"signed="false">
<!--ImageCount express the number of images contained by the .CUR file -->
<Relationtype="count" of="Entries" />
<Relationtype="count" of="Image" />
</Number>
</Block>
</DataModel>
String元素的参数
- value:这个参数告诉Peach它应该期望什么样的值来匹配这个字段。需要注意的是,指定一个值也会内在地为Peach提供字符串的长度。
- valueType:这个参数告诉Peach如何解释我们的数据。由于规范将其定义为十六进制值,我们需要指定一个十六进制的valueType,否则Peach会将其解释为文本字符串“00000200”。
- token:这个参数通知Peach这个字符串必须存在,Peach需要在继续执行剩下的区块之前对其进行识别。如果没有出现匹配的对象,Peach将继续进入我们DataModel中的下一个块。
- mutable:这个参数告诉Peach是否要对这个字段进行模糊测试。如果将这个参数设置为false,就是告诉Peach不要直接修改这个字段,但是,这并不意味着这个数据不会被相邻的、被模糊测试的字段所覆盖。在这个例子中,我们选择将这个字段标记为不可更改,因为一些处理文件的应用程序会自动丢弃签名(魔术字节)损坏的文件。
Number元素的参数
- size:它定义了Number元素的大小。当使用Number元素时,大小是以位而非字节为单位来定义的。
- endian:它定义了数字的字节顺序,Peach会自动默认为little-endian顺序。
- signed:它决定了数字的符号(有符号或无符号)。如果没有指定这个选项,Peach默认为有符号的(true)。
至于剩下的“Entries”和“Image”块,这里就不做详细介绍了:
<Block name="Entries"minOccurs="0" length="16">
<Numbername="Width" size="8" endian="little"signed="false"/>
<Numbername="Height" size="8" endian="little"signed="false"/>
<Numbername="ColorCount" size="8" endian="little"signed="false"/>
<Numbername="Reserved" size="8" endian="little"signed="false"/>
<Numbername="xHotSpot" size="16" endian="little"signed="false"/>
<Numbername="yHotSpot" size="16" endian="little"signed="false"/>
<Numbername="SizeinBytes" size="32" endian="little"signed="false">
<!--ImageBlob.size=SizeinBytes-InfoHeader.length -->
<Relationtype="size" of="Image" />
</Number>
<Numbername="FileOffset" size="32" endian="little"signed="false"/>
</Block>
<Block name="Image"minOccurs="0">
<!--InfoHeader -->
<Numbername="Size" size="32" endian="little"signed="false"/>
<Numbername="Width" size="32" endian="little"signed="false"/>
<Numbername="Height" size="32" endian="little"signed="false"/>
<Numbername="Planes" size="16" endian="little"signed="false"/>
<Numbername="BitCount" size="16" endian="little"signed="false"/>
<Numbername="Compression" size="32" endian="little"signed="false"/>
<Numbername="ImageSize" size="32" endian="little"signed="false"/>
<Numbername="XpixelsPerM" size="32" endian="little"signed="false"/>
<Numbername="YpixelsPerM" size="32" endian="little"signed="false"/>
<Numbername="ColorsUsed" size="32" endian="little"signed="false"/>
<Numbername="ColorsImportant" size="32" endian="little"signed="false"/>
<!-- ImageData -->
<Blobname="ImageBlob"/>
</Block>
长度关系
这些关系是Peach最强大的功能之一。在本例中,我们可以继续使用长度关系来告诉Peach:“ImageBlob”的长度位于“SizeinBytes”中。此外,这个关系是双向的,所以当我们开始进行模糊测试时,如果“ImageBlob”中的数据量增加,Peach就会更新“SizeinBytes”,使其包含正确的值(或者不包含,具体取决于模糊测试的策略)。
长度关系参数
- type:定义要使用的关系类型。在本文中,我们只讨论“size”关系。
- of:指出在这个关系中要引用哪种元素。
我们现在应该添加StateModel了,具体如下所示:
<!-- Define a simple state machine that will writethe file and
then launch aprogram using the FileWriterLauncher publisher -->
<StateModel name="State"initialState="Initial">
<Statename="Initial">
<!--Write out contents of file -->
<Actiontype="output">
<DataModel ref="Cur" />
<!--Directory from where to load test cases to mutate -->
<Data name="data"fileName="C:\peach\samples/*.cur"/>
</Action>
<!--Close file -->
<Actiontype="close" />
<!--Launch the file consumer -->
<Actiontype="call" method="LaunchViewer"publisher="Peach.Agent"/>
</State>
</StateModel>
StateModel参数
- Name:该参数用于为这个StateModel定义一个名称。对于较为复杂的Pit文件来说,可能会包含多个StateModel,所以,最好为其定义一个唯一的名字,以备以后需要引用这个元素时使用。
- initialState:顾名思义,该参数定义了StateModel中要使用的第一个State。每个StateModel可以根据fuzzer的要求使用多个State。
幸运的是,我们只需要一个State就行了;至于多个State的情况,通常出现在复杂的网络模糊测试中,而在文件格式模糊测试中很少出现。每个State的用途,实际上就是充当Action元素的容器。
Action元素用于指示Peach如何处理我们的数据。在修改模板中定义的Action之前,让我们先来简单介绍一下Action元素的可用选项。
- type:它定义了操作的目的。例如,我们的第一个操作类型是“open”。这个操作负责打开文件,并为要执行的进一步操作做好准备。
- Publisher:它定义了我们要把这个数据传递给哪个发布者。我们的操作指示Peach使用该文件发布者来打开文件、写入模糊测试数据并保存文件。最后一个操作定义了负责启动要进行模糊测试的目标应用程序的“launch”发布者。
- method:它标识了应用程序的消费者。该参数只对Action类型“call”有效。
Agent
Agent负责监控我们的应用程序,并记录我们的fuzzer可能触发的任何崩溃。对于Peach框架来说,它使用的是微软的WinDbg插件“!exploitable”,它能够对崩溃的可利用性进行分类和评估。关于该插件的更多信息,请访问https://msecdbg.codeplex.com/。
<Agent name="WinAgent">
<Monitorclass="WindowsDebugger">
<!--Target process and command line to open "fuzzed" test case -->
<Param name="CommandLine" value="C:\Program Files(x86)\FastStone Image Viewer\FSViewer.exe fuzz.cur" />
<!--WinDbg folder -->
<Param name="WinDbgPath" value="C:\Program Files(x86)\Windows Kits\10\Debuggers\x64\" />
<Param name="StartOnCall" value="LaunchViewer"/>
</Monitor>
<Monitorclass="PageHeap">
<!--Target process name -->
<Param name="Executable"value="FSViewer.exe"/>
<!--WinDbg folder -->
<Param name="WinDbgPath" value="C:\Program Files(x86)\Windows Kits\10\Debuggers\x64\" />
</Monitor>
</Agent>
实际上,元素<Agent>用于充当监视器配置的容器。在我们的Agent容器中,可以看到模板被配置为使用Windows Debug Engine作为我们的主要监视器。此外,我们还可以看到,在这个监视器中定义了两个附加参数。第一个参数“CommandLine”用于定义要启动和监控的目标应用程序的路径,模糊测试数据的文件名,以及启动应用程序可能需要的任何标志。
提示: 如果您发现正在模糊测试的应用程序已经被启动了,但它似乎没有加载相应的模糊测试数据,则请尝试添加被模糊测试的文件完整路径,并用HTML编码的引号将其括起来(例如,"C:\peach\fuzzed.cur")。
我们的下一个参数定义了在附加调试器之前要等待的方法。我们需要将其改为在StateModel中为<Action type=”call” …/> 元素提供的值。
之后,我们还可以看到,这里将启用PageHeap作为我们的监视器。这个监视器用于调试和记录影响应用程序堆的数据;这个参数只接受可执行文件的名称,并且不需要完整的文件路径。
Test部分
我们的模板中,Test部分负责将所有的东西捆绑到一起。它不仅会将我们的State和Agent配置关联起来,并允许我们配置自己的发布者,它负责接收模糊测试数据和向磁盘写入模糊测试数据。现在,让我们来看看模板中这部分的配置情况。
<Test name="Default">
<Agentref="WinAgent" platform="windows"/>
<StateModel ref="State"/>
<Publisher class="File">
<!--"Fuzzed" Test Case Name-->
<Paramname="FileName" value="fuzz.cur" />
</Publisher>
<Logger class="Filesystem">
<!--Crashes Folder Location -->
<Param name="Path" value="C:\logs\" />
</Logger>
</Test>
在这里,我们让Peach使用我们指定的Agent和名为State的StateModel。
下面是最终的pit文件,其中添加了State Model,Agent和Test;当然,为了便于读者理解,我们也给出了详细的注释:
<?xml version="1.0" encoding="utf-8"?>
<Peach xmlns="http://peachfuzzer.com/2012/Peach" xmlns:xsi="http://www.w3.org/2001/xmlSchema-instance" xsi:schemaLocation="http://peachfuzzer.com/2012/Peach ../peach.xsd">
<!-- Define our file format -->
<DataModel name="Cur">
<Block name="Signature" minOccurs="1" maxOccurs="1">
<!-- Reserved + Type (expressed in Little Endian Format) -->
<String name="CurSignature" value="0x00000200" valueType="hex" token="true" mutable="false"/>
<Number name="ImageCount" size="16" endian="little" signed="false">
<!-- ImageCount express the number of images contained by the .CUR file -->
<Relation type="count" of="Entries" />
<Relation type="count" of="Image" />
</Number>
</Block>
<Block name="Entries" minOccurs="0" length="16">
<Number name="Width" size="8" endian="little" signed="false"/>
<Number name="Height" size="8" endian="little" signed="false"/>
<Number name="ColorCount" size="8" endian="little" signed="false"/>
<Number name="Reserved" size="8" endian="little" signed="false"/>
<Number name="xHotSpot" size="16" endian="little" signed="false"/>
<Number name="yHotSpot" size="16" endian="little" signed="false"/>
<Number name="SizeinBytes" size="32" endian="little" signed="false">
<!-- ImageBlob.size=SizeinBytes-InfoHeader.length -->
<Relation type="size" of="Image" />
</Number>
<Number name="FileOffset" size="32" endian="little" signed="false"/>
</Block>
<Block name="Image" minOccurs="0">
<!-- InfoHeader -->
<Number name="Size" size="32" endian="little" signed="false"/>
<Number name="Width" size="32" endian="little" signed="false"/>
<Number name="Height" size="32" endian="little" signed="false"/>
<Number name="Planes" size="16" endian="little" signed="false"/>
<Number name="BitCount" size="16" endian="little" signed="false"/>
<Number name="Compression" size="32" endian="little" signed="false"/>
<Number name="ImageSize" size="32" endian="little" signed="false"/>
<Number name="XpixelsPerM" size="32" endian="little" signed="false"/>
<Number name="YpixelsPerM" size="32" endian="little" signed="false"/>
<Number name="ColorsUsed" size="32" endian="little" signed="false"/>
<Number name="ColorsImportant" size="32" endian="little" signed="false"/>
<!-- Image Data -->
<Blob name="ImageBlob"/>
</Block>
</DataModel>
<!-- Define a simple state machine that will write the file and
then launch a program using the FileWriterLauncher publisher -->
<StateModel name="State" initialState="Initial">
<State name="Initial">
<!-- Write out contents of file -->
<Action type="output">
<DataModel ref="Cur" />
<!-- Directory from where to load test cases to mutate -->
<Data name="data" fileName="C:\peach\samples/*.cur"/>
</Action>
<!-- Close file -->
<Action type="close" />
<!-- Launch the file consumer -->
<Action type="call" method="LaunchViewer" publisher="Peach.Agent"/>
</State>
</StateModel>
<Agent name="WinAgent">
<Monitor class="WindowsDebugger">
<!-- Target process and command line to open "fuzzed" test case -->
<Param name="CommandLine" value="C:\Program Files (x86)\FastStone Image Viewer\FSViewer.exe fuzz.cur" />
<!-- WinDbg folder -->
<Param name="WinDbgPath" value="C:\Program Files (x86)\Windows Kits\10\Debuggers\x64\" />
<Param name="StartOnCall" value="LaunchViewer" />
</Monitor>
<Monitor class="PageHeap">
<!-- Target process name -->
<Param name="Executable" value="FSViewer.exe"/>
<!-- WinDbg folder -->
<Param name="WinDbgPath" value="C:\Program Files (x86)\Windows Kits\10\Debuggers\x64\" />
</Monitor>
</Agent>
<Test name="Default">
<Agent ref="WinAgent" platform="windows"/>
<StateModel ref="State"/>
<Publisher class="File">
<!-- "Fuzzed" Test Case Name-->
<Param name="FileName" value="fuzz.cur" />
</Publisher>
<Logger class="Filesystem">
<!-- Crashes Folder Location -->
<Param name="Path" value="C:\logs\" />
</Logger>
</Test>
</Peach>
<!-- end -->运行我们的Fuzzer
在尝试运行任何东西之前,一定要先用PeachValidator检查提交给Peach的xml(Pit文件),以确保其格式是有效的,并且在解析指定的文件格式时不会出现任何错误。
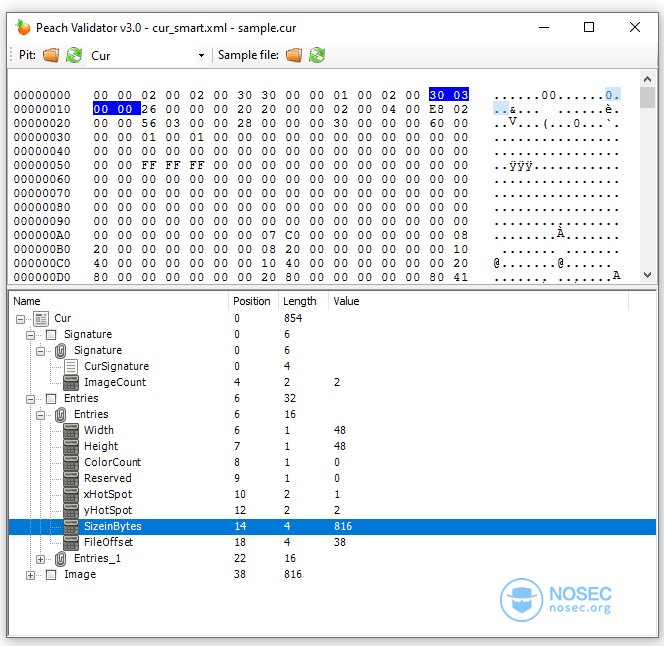
现在,我们已经生成了Pit文件,但是在启动fuzzer之前,我们还需要先进行一次测试。第一个测试用例实际上并不对我们的样本数据进行模糊测试;而是将解析样本的压缩文件,重新生成另一个副本,并将这些数据提供给我们的目标应用程序。
为此,我们可以运行以下命令:
peach.exe -1 --debug cur_smart.xml
执行上面的命令后,Peach会继续使用前面创建的DataModel来解析测试性质的CUR文件,并将输出结果转储到一个文件中,但是,这里不会对其进行任何突变处理,而是直接将其提供给目标应用程序。这本质上是一次试运行(dry run)。Peach以此来确定Application是否能够正确地接收我们提供的文件,以及Agent能否检测到这个进程并等待它退出(或被杀死)。如果抛出故障或出错,第一个测试用例将会失败,Peach(即使没有-1参数)也会退出模糊测试过程。
然而,如果一切顺利,你应该看到类似下面的内容:
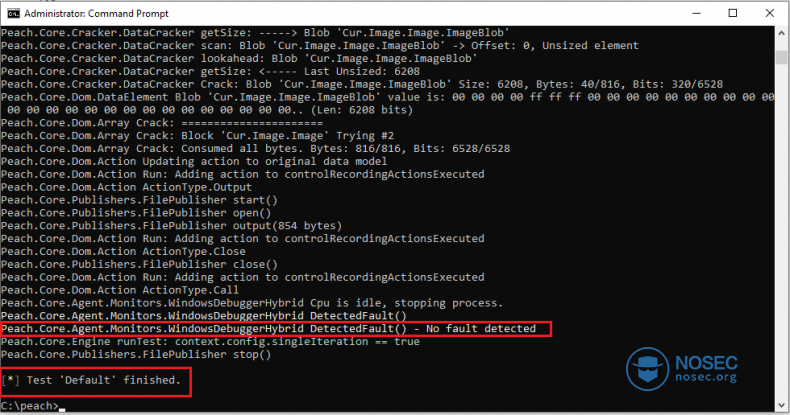
在我们启动fuzzer之前,我们还要熟悉一个额外的命令行参数。我们知道,Peach使用的随机突变策略会为我们提供一个种子值,这样一来,万一我们的fuzzer崩溃了,或者我们以后想复现一个测试用例,我们可以指定种子值和迭代次数,以便能够返回到那个精确的测试用例。种子值是在每个新测试开始时生成,并且存储在指定日志目录中的status.txt文件中。所以,如果进行模糊测试的应用程序在测试用例#100上崩溃,使用的种子值是1234567890.12,我们可以通过输入以下命令来恢复我们的测试会话:
peach.exe --seed 1234567890.12 --skipto 100cur_smart.xml崩溃及其分类
如果我们让fuzzer运行几个小时(实际上,我让fuzzer运行了半天,大约出现了104次不同的崩溃),将会得到一个包含崩溃数据和一些文件的目录。
- txt: 它为我们提供了许多重要的信息,以帮助我们重新考察之前的模糊测试的结果。它列出了模糊测试的开始时间,使用的种子值,以及特定的测试案例和用于导致崩溃的文件。
在Faults目录中,还有一些子目录,每个子目录对应于一种特定的崩溃类别;这些都是由“!Exploitable”确定的。
例如,在UNKNOWN_0x7e5b5c0d_0x7e2c470d中,我们可以看到一些目录,如11958, 25903等,它们都是以触发崩溃的测试用例号来命名的。打开其中一个目录,我们会看到以下内容:
- action_1_Output_Unknown Action 1.txt:这个文件包含了触发崩溃时提供给应用程序的数据。在重现崩溃和确定可利用性时,这些数据是非常有用的。
- txt & WindowsDebugEngine_description.txt:这些文件存放了崩溃时产生的堆栈跟踪、寄存器值以及“!Exploitable”生成的信息。
值得一提的是,虽然“!Exploitable”在识别独特的崩溃方面很有用,但是在评级方面,最好还是由我们自己来手动审查,因为它只看第一个异常,而不会关心之后会发生什么,例如,读取访问违规会触发软件内部处理的异常,导致后来的EIP会被用户控制的数据所覆盖。
(1630.234c): Access violation - code c0000005 (firstchance)
First chance exceptions are reported before anyexception handling.
This exception may be expected and handled.
*** WARNING: Unable to verify checksum for C:\ProgramFiles (x86)\FastStone Image Viewer\FSViewer.exe
FSViewer+0x1bdf49:
005bdf49 8b00 mov eax,dword ptr [eax] ds:002b:1101ffff=????????
eax=1101ffff ebx=00481c9c ecx=42bef4a6 edx=000005f0 esi=00481c9cedi=07251dfc
eip=005bdf49 esp=0019f568 ebp=0019fa10 iopl=0 nv up ei pl nz ac po cy
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00010213
从寄存器和故障指令来看,FSViewer似乎是将一些非预期的内容读到了EAX中,但是,如果我们跳过第一个异常,我们得到下面的内容:
Access violation - code c0000005 (first chance)
First chance exceptions are reported before anyexception handling.
This exception may be expected and handled.
1111110f ?? ???
eax=00000000 ebx=00000000 ecx=1111110f edx=77a59f80esi=00000000 edi=00000000
eip=1111110f esp=0019efb8 ebp=0019efd8 iopl=0 nv up ei pl zr na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00010246
其中,EIP寄存器已被值“1111110f”所覆盖。如果我们能够控制如何和从何处读取这个值,我们就可以控制应用程序流了!
如果我们在调试器内打开FSViewer应用程序,并解析进行模糊测试的CUR文件,我们就会发现以下SEH记录已经被破坏了。
CVE-2021-26236:根本原因分析
如果我们将崩溃文件最小化,并与我们提供给fuzzer的基线进行对比,我们就会发现Peach改变了BitCount结构的值,并且使其过大了。 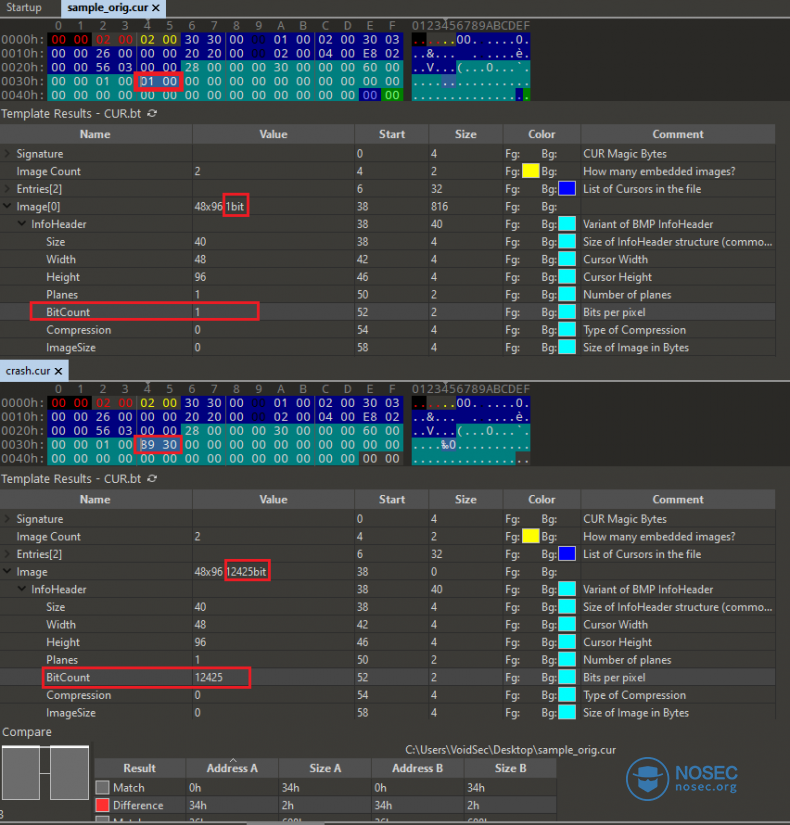
利用010 Editor比较文件的差异
幸运的是,通过查看最终到达EIP的值,我们可以发现,在文件中可以找到这个值的某些实例,并且如果覆盖其中的某些实例的话,我们就能够控制EIP了。
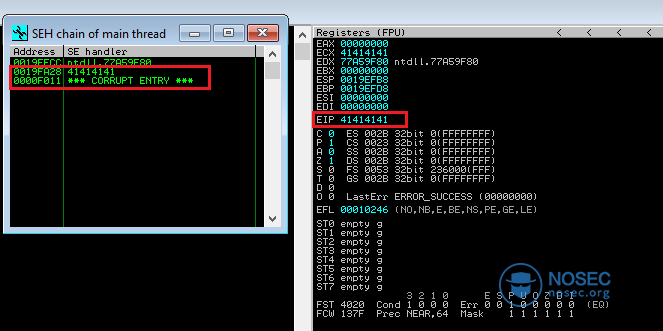
控制EIP
现在,我们已经知道了崩溃发生的位置,接下来,我们只需要了解为什么会发生崩溃即可。
由于FSViewer提供了一个内嵌的“文件资源管理器”来预览支持的图像文件,因此我们可以假设,当进入一个新的目录时,它将搜索并解析所有受支持的图像文件,以创建一个预览。
考虑到这一点,我已经在x64dbg中加载了FSViewer,并使用API Break插件在Windows ReadFile API上设置了一个断点。
在FSViewer.exe+BA64处有一个ReadFile调用,它会被触发很多(上千次),其中有几次是用于解析我们的文件。因此,我们知道某些结构体的大小,可能会被破坏,例如,当edi==0x28时。
不过,这里为什么寄存器是edi,为什么这里的值偏偏是0x28呢?
从ReadFile Windows API原型中我们可以看到:
BOOL ReadFile(
HANDLE hFile,
LPVOID lpBuffer,
DWORD nNumberOfBytesToRead,
LPDWORD lpNumberOfBytesRead,
LPOVERLAPPEDlpOverlapped
);
由于我们处于x86进程中,因此,在API可以接收值之前,需要将所有参数压入堆栈;如果我们查看位于FSViewer.exe+BA64处的ReadFile调用,就可以确切地看到这一点:
0040BA60 | push eax | LPDWORD lpNumberOfBytesRead
0040BA61 | push edi | DWORD nNumberOfBytesToRead
0040BA62 | push esi | LPVOID lpBuffer
0040BA63 | push ebx | HANDLE hFile
0040BA64 | call <JMP.&ReadFile> | ReadFile
其中,EDI寄存器用于处理NumberOfBytesToRead参数的值,而0x28则是BitCount字段所在的BITMAPINFOHEADER结构体的固定长度。
在FSViewer.exe+1BDEC8处,我们可以看到以下指令:
005BDEC8 | movzx eax, word ptr ss:[ebp-0x8A]
005BDECF | mov dword ptr ss:[ebp-0x34], eax
其中,BitCount字段将会从缓冲区读入EAX,然后保存在EBP-0x34处。我们在EBP-0x34处设置了一个硬件断点,这样的话,每当软件读取它时,都会发生中断。
稍后,在fsviewer.exe+1bdf01处:
005BDF01 | mov ecx, dword ptr ss:[ebp-0x34]
005BDF04 | mov eax, 0x1
005BDF09 | shl eax, cl
005BDF0B | mov dword ptr ss:[ebp-0x40], eax
我们的BitCount值被读入ECX,EAX被加载为1,这样就会导致发生崩溃:
指令shl eax, cl将对EAX进行逻辑移位操作(向左),共移动CL字节。由于我们控制了EXC中的字节,从而控制了CL中的字节,所以,我们就可以控制该指令的结果。就这里来说,由于计算结果 ( 0x2000000 ) 大于一个32位有符号的整数的取值范围,因此,它无法被完整地保存到EAX中。
现在,EAX寄存器中保存的值为0x200,之后,它又被移位了2个字节,所以,它现在的值为0x800。
之后,上面的那个值被ReadFile函数用来读取缓冲区中的0x800字节(因此,这就意味着我们可以直接控制读取的字节数了),由于无法控制我们应该读取多少字节,因此,我们最终破坏了堆栈上的SEH链。
现在,我们面临的只是一些循环模式和偏移计算的问题,接下来,我们开始介绍这个漏洞的利用方法。
漏洞的利用方法
在这里,我们不打算讨论如何创建漏洞利用代码(尽管从学习的角度来看,这件事情超级有趣),因为这篇文章已经够长了,但如果有什么不清楚的地方,欢迎随时与我进行交流(如果你对Windows的漏洞利用代码开发感兴趣,可以访问https://www.corelan.be/index.php/articles/)。
尽管FastStone Image Viewer没有采用任何缓解措施,如DEP、ASLR或Safe SEH机制,但我为Windows 10创建的exploit代码也提供ASLR和DEP的绕过功能(也就是说,即使启用了这些缓解措施,如果没有修复底层漏洞的话,还是容易受到该漏洞的影响)。我建议有兴趣的读者可以翻阅一下这个exploit的源码,以便了解文件格式结构体是如何保存的,ROP Chain和Stack Pivot被放置在哪里,存在哪些限制条件,以及如何改进该exploit以使其更为可靠;当然,欢迎大家到Twitter和Discord(VoidSec#3405)上来骚扰我。
当然,相关的exploit代码可以在我的GitHub上找到(https://github.com/VoidSec/Exploit-Development/tree/master/windows/x86/local/FastStone_Image_Viewer_v.7.5)。
关于下一篇文章
在下一篇文章中,我将为读者详细介绍在某款流行软件中发现的一系列的安全漏洞,如果组合利用这些漏洞(从任意文件写入到本地提权(LPE)/权限提升(EoP)),攻击者就能成功实现命令执行攻击。
相关资源与参考资料:
- CUR FileFormat Specification
- 010 EditorTemplate
- File FormatReverse Engineering
- Peach Fuzzing:Getting Started
- PeachFuzzer: Data Modelling
原文地址:https://voidsec.com/fuzzing-faststone-image-viewer-cve-2021-26236/


最新评论