让网络空间测绘技术不再那么飘忽不定
 xiannv 2000天前
xiannv 2000天前前一段时间,朋友发给我一篇英文文章(https://link.springer.com/chapter/10.1007/978-981-33-4922-3_15),说这篇名为《A Survey on Cyberspace Search Engines》的文章里面把几家做网络空间测绘的平台进行了比较。通常我对于这种都不太在意,没有比做让用户认可的技术更重要的事情了,用户都是用脚投票,好用我就来,不好用就走。用户能够感知到你的用心程度,所以不必尝试去证明什么,客户能做判断。尤其还是英文的文章,我不觉得能对99%都是国内用户的fofa平台分析出个什么来,至少目前我还没有精力关注这一块。一直到后来,经过人家提醒,我才发现第一作者是来自国内某权威单位的专家,由此我不得不重视和关注。
在我深入的分析了文章之后,我有两个很清晰的感觉。一是网络空间测绘这个网络安全细分领域的技术,得到了来自权威部门的关注和认可,这对我们这些一直坚持在技术一线的团队和公司来说,是一件非常非常值得开心的事情,这比我们自说自话要有意义得多。由于一直没有特定的行业标准和资质品类,至今类似公司的相关产品申请的销售许可都是往漏洞扫描器去挂靠。如果得到的响应地关注,我们可以预见在不远的将来,行业能够得到更加规范的发展。二是由于这门技术的特殊性(主要还是大家对技术总结的比较少),导致一些非常基础的概念大家都并有能够达成共识,产生了一些理解上非常明显的“偏差”。想了想,我觉得我们还是有责任来总结一些我们的理解,提供一些小小的建议,仅供大家参考。
一)参考链接比较随意,非权威来源,且缺少价值信息;
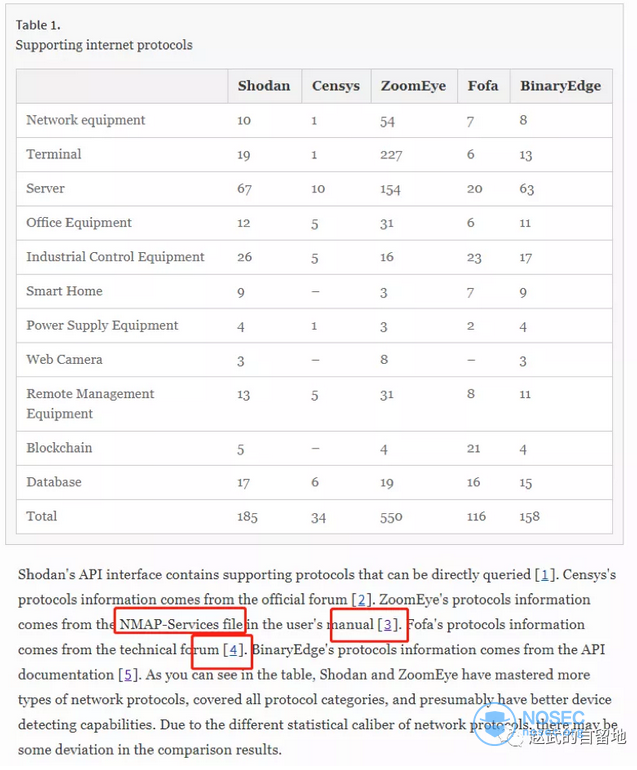
根据文章链接内容3(https://www.zoomeye.org/doc?Thechannel=user#d-service),作者尝试说明zoomeye的用户手册中提到了协议来源于nmap-services的描述。点进去页面后却发现并没有任何内容提到这一点,且连nmap字样都看不到。我们姑且认为网站进行了改版,以前的信息看不到了,那么我们思考一个问题,我们可以宣称参考了某个规范,它可以解读为a)我们部分实现了里面的协议;b)我们全部实现了所有协议;官方未必有这个意思,不过文章中显然采信了第二种假设。于是我们做了一个很小的随机抽样测试,随机选择了nmap-services中的50个协议进行确认,zoomeye只实现了其中的11种,这个证伪的过程是比较简单的(具体测试方法,如果相关同事有兴趣,可以联系我们)。从另一个角度,如果以后各网络空间测绘引擎在各自官网都写上,我们的“协议参考了nmap以及wireshark”,这个领域对比是不是就简单了?
文章参考链接的4(https://www.freebuf.com/articles/ics-articles/196647.html),名称叫做《2018年工业控制网络安全态势白皮书》。文章说fofa的协议列表来源于这篇文章,事实上引用的来源文章里面非但完全没有提及fofa,而且来源明确说了信息是根据“东北大学谛听网络安全团队根据“谛听”网络空间工控设备搜索引擎收集的各类安全数据”。这种“张冠李戴”的情况出现在一个严谨的学术论文,实属难以理解。退一万步说,2018年的分析也不能跟另外几家的现在去比较,很简单的逻辑是:仅工业控制协议,Fofa从2018年起都增加了数十个。
基于上面的分析,我们认为数据的参考是不可取的,其实国内各平台应该也愿意配合官方进行标准的制定,如果有权威部门进行汇总整理,由各平台自行保送,加上权威部门的验证确认更合理一点。一定要确认,因为参考了不一定实现了,实现了不一定准确了,准确了不一定全网数据采集全面了。对比就是为了区分不同平台的优劣势,大家选择发力方向不同,结果自然不同。
二)对比的核心维度概念模糊,存在不一致性;
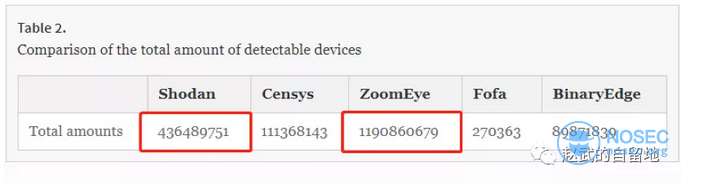
其中这一张图比较有代表性。我们稍微介绍一下在网络空间测绘领域比较重要的几个基本数据的统计维度:
1)网络资产数:通俗一点就是数据记录条数,技术一点就是用什么作为存储的key键值。不同的平台实现的机制并不一致,比如shodan是按照ip:port存储,fofa和zoomeye是按照host:port存储,360的quake平台是根据ip:port:date存储。因为shodan选择的是只针对ip层面进行分析,所以他们直接放弃了主机域名的分析,一个ip可以对应任意多个域名,在以前的一些文章我已经说明了,为什么用shodan做针对某个企业的互联网暴露面梳理效果比较差。其他平台都采用了网站域名的分析,数据量差别比较大,目前fofa的主机域名数暂时上来说优势还是有一点的。基于host:port的方式会存储两个数据存储:一个叫热数据,比如昨天发现了1.1.1.1:80,今天又发现了,在你热数据中会发生覆盖,只会有一条最新的;另一个叫冷数据或者叫历史数据,大家按名字理解就好。quake平台稍微特殊,由于加入了date作为key,会导致一个ip的一个端口,你可以查询出来多条数据。
2)独立IP数:基于上面的说法,大家就知道,记录数不代表ip数,一个ip开了多个端口,就对应多条记录。大家通常对ip比较理解,所以fofa在你搜索的时候会明确告知你聚合后的ip总数有多少。在shodan,你直接查询一个端口比如port:80它给出来的统计数据其实就是准确的ip个数,其他平台大家可以自行分析方法。在硬件(物联网或者服务器)领域,IP和硬件是一一对应的,但是在软件应用领域,一个IP可以承载任意多个应用,这也就是我们俗称的攻击点。
3)指纹规则数:一条指纹规则简单来说就是能够用于识别某一类设备或者软件的查询语句。这是fofa最先发明的,早期各平台都是内嵌了简单的一些设备识别库,也不提供html等大文本的关键字检索,所以用户无法自定义和保存。fofa一开始的设计理念就是用户更懂场景,所以要放开这种方法,让用户来自定义识别的语法,然后可以保存下来方便后续使用。最初我们叫应用规则库,后来慢慢叫法就多了,有叫指纹库的,也有叫规则集的,还有叫软硬件识别库的。一条指纹可以对应任意多条设备。目前论指纹规则库,fofa还是有一点点的优势的。
4)特定规则集匹配的网络资产数:如上所述,一个规则查询的结果其实就是匹配的网络资产数,所有指纹规则库匹配的网络资产数基本就是全库了。
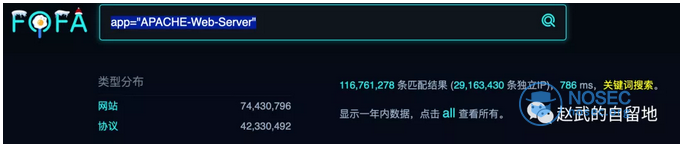
如果上面说的还是难以理解,我们通过上图这个非常简单的示例来说明:我们尝试搜索互联网中开放的Apache网站服务器数量,我们可以在fofa中检索app="APACHE-Web-Server",这时返回的11675万代表了互联网中存在的所有使用了这个服务器的资产数,其中网站和协议是可以有重合的,分别对应7442万和4232万,因为一个80端口在协议中是存在的,但是它可能假设多个域名。独立ip只有2916万,是因为一个ip的apache服务器可以绑定到多个端口。
回到上面的那张对比图,就是一个非常有意思的结果了:shodan对应4亿,zoomeye对应11亿,fofa对应27万。我相信每一条数据作者都是经过思考和挑选的,只是没能梳理清楚,到底是全网的网络资产数,还是独立IP数,还是指纹规则库的数量,以及特定规则集匹配的网络资产数,甚至是可能没有分清是热数据还是包含了历史数据。如果不在一个维度来对比,也就没有太大的参考价值。
另外,值得强调的是,哪怕是在一个维度进行对比,单纯的对比数据也存在很大的误导性,比如shodan只拿出一个月的数据作为热数据,老的数据它都不展示(没覆盖的也不显示),quake是把历史数据也展示出来了,所以实际上你可能很难统计出一个公允的结果。我们要考虑一定时间内数据的获取能力(注意必须要考虑一定时间内),要考虑数据的深入性和准确性(比如协议或者规则)。如果没有这些,就必然出现各大平台玩起了刷数据的游戏,乐此不疲。如果shodan隐藏实力,我们向它学习还是有意义的
三)数据抽样测试的参考标准存在差异,直接影响了结果;
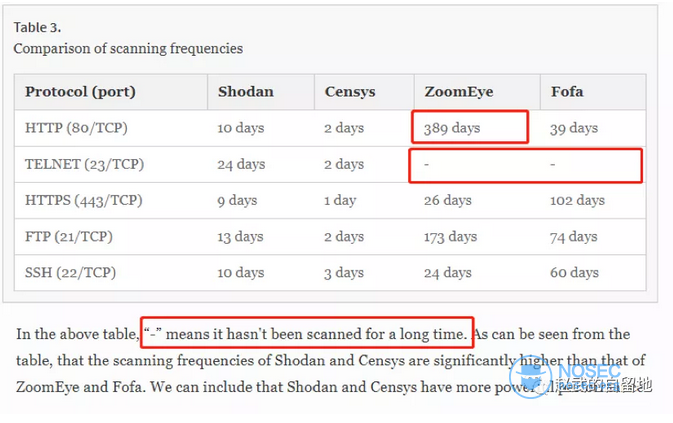
这里我必须帮zoomeye说一句话:如果作为互联网使用量最大的http协议一次轮巡需要超过一年时间,基本上这个平台就废了,zoomeye绝对不至于这么不济。censys的周期是对的因为他们的端口数量是最少的所以相对而言周期是最快的,shodan的周期稍微有些偏差,zoomeye和fofa的时间则是存在很大的问题。这几个协议是互联网用的最多的协议的前几名,数量大变化快,能够很好的用户实战体系中,所以各家都比较重视,不会存在不抓取的情况。
在图中出现了“-”说明没有扫描数据,而shodan和censys有,我大胆地推测拿出来的对比测试的IP是以shodan或者censys为主的(这一点我只是个人推测)。由于网络变化太快,一个ip端口上线后快速下线,所以哪怕在一天一次这种极速轮询过程中,一定会出现一些IP刚好只被一个平台抓到,在其他平台都没有抓取到。要举一个反证实在太容易了,比如24.232.7.242这个IP,大家到各平台搜索一下,你会发现这个ip对应的23端口只存在于fofa平台,这仅仅能证明那一天刚好被fofa抓到了,其他平台到它那去的时候23端口已经关闭,但这一定证明不了由此shodan或者censys的扫描频率是“-”。
实际运营过程中,大家会把不同的端口进行分组,一个端口可以存在不同的扫描集群中,比如一个大端口(覆盖大量ip的端口)可能同时并行的存在不同的端口组策略中,并行地进行扫描。又由于大网的端口扫描一定是随机IP的,一定存在30%的网络抖动的,所以依靠一次完成95%的数据相似度根本就不可能。大家会进行多轮不断的轮询尽可能多的覆盖最新的上线资产,那种尝试用nmap实现端口扫描和协议识别的网络空间测绘技术, 我暂时打一个问号,宣称即快还全还准的,内网可以大网很难。
四)其他一些细节点;
文章中还有一些点可能值得商榷,比如:
- 协议分类和设备分类是否为同一个概念?
- Domain databa se这一项提到了只分析了top 100万alexa排名域名的censys,没有提域名存量最多的fofa?
- 探针分布的分析维度?
这些细节的点倒无关痛痒,只是大家对权威论文的理解是分析方法应该经得起公示经得起挑战的,如果存在诸多不明确,容易引起误会。
上面提到了这么多,稍微做一些总结。首先毫无疑问,shodan是第一个开拓者,大家或多或少受它的影响,站在老师傅的肩膀上前行。今天老师傅还是老师傅,我们距离它还有十万八千里,无论是基础的投入,还是数据的严谨性,还是历史存量数据的积累和功能的丰富程度等等,国内的平台暂时都还难以望其项背。我们当然是存在弯道超车的可能性的,我们也看到了很多机会,只是在当前阶段,我们任何一家单方面宣布是世界第一,终究会贻笑大方。这不是一个广告时间,而是一个让我们值得深思的时刻,论实战化的能力,我们距离那些对手还是相去甚远,如果真的需要对攻对防,我们的这些储备真的够了吗?
我们要关注各种数据的对比,根据我们这些年对网络空间测绘的理解,网络空间测绘的技术对比维度,应该聚焦于实战,应当包含如下一些:
1. 资产总量(历史存续数据、域名数据等)
2. 支持的端口和协议
3. 搜索和展示字段数
4. 数据更新速度(每周、每月)
5. 数据准确度(协议、规则等)
6. 协议解析深入度
7. 产品规则数
8. 活跃用户规模
我们呼吁相关的部门能够针对网络空间测绘这一个细分领域给予指导,能够出台相关的技术标准和规范。一切都是为了满足实战化,以及持续性的常态实战化。针对一些概念和名称进行标准化,针对搜索关键字和语法进行规范化,针对数据的存储格式统一化,对于资产的分类和分层也能归一化。进而制定出对应的技术评判标准,最终引导行业步入健康有序的发展,为国家创造更多更好的技术输出。
◆来源:赵武的自留地
◆本文版权归原作者所有,如有侵权请联系我们及时删除



最新评论