机器学习:通过按键声音破解你的密码
 iso60001 2456天前
iso60001 2456天前我记得在不久以前,最先进的机器学习还只是用来在一堆图片中找出猫和狗。而在这短短的几年时间里,机器学习领域发生了难以置信的变化,研究人员以不再执着于分辨各种动物,而是开始把机器学习的枪口瞄准人类。这篇文章我将介绍一种利用机器学习破解密码的方法。

更具体地说,我们能否仅通过键盘声音来确定某人正往电脑上输入什么?为此,我专研于了一个名为kido(= keystroke decode)的项目,以探索其中的可能性(https://github.com/tikeswar/kido)。
大纲
我这里将大致描述一下整体流程。
数据收集和准备
训练和评估
测试和误差分析(提高模型精度)
总结成果,上传GitHub
在这个项目中我使用了Python、Keras和TensorFlow。
数据收集
第一步,我们如何收集数据来训练模型?
这一步有很多方法实现,最后我选择使用我的MacBook Pro键盘打字,并用QuickTime播放器通过内置的麦克风记录打字的声音。
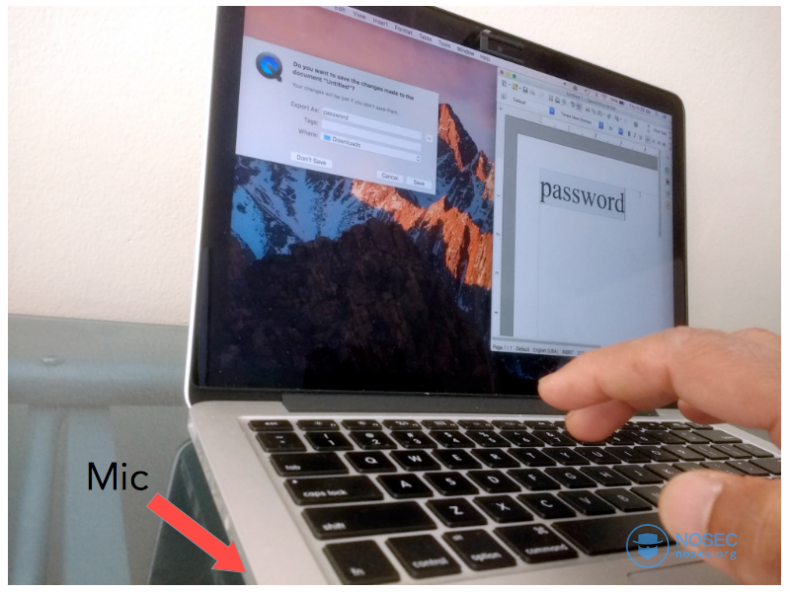
在初期我打算以自己为目标,尽量避免垃圾数据的干扰。
数据准备
下一步是准备数据,方便我们将其输入神经网络(Neural Network)进行训练。
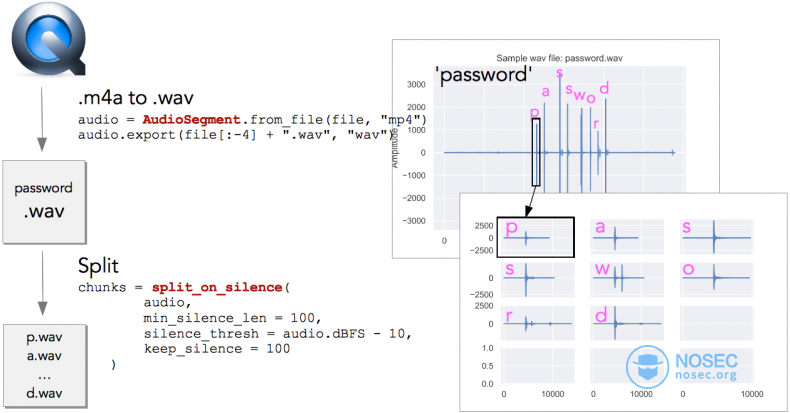
Quicktime会将录制的音频保存为mp4格式,那么我们首先将mp4转换为wav格式,因为有现成的Python库可以处理wav文件。上图中的每个峰值对应一个击键,因此可以使用split_on_silence函数将音频分割成单独的数据块,这样每个数据块只包含一个字母。
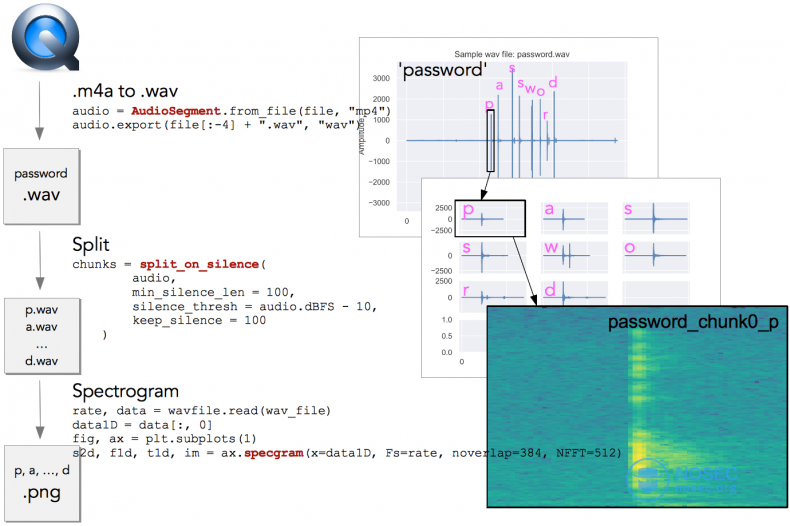
接着将单独的数据块转换成光谱图(如上图)。这样对于每个按键声音我们有了更丰富的图像展现,使用卷积神经网络处理也更加容易。
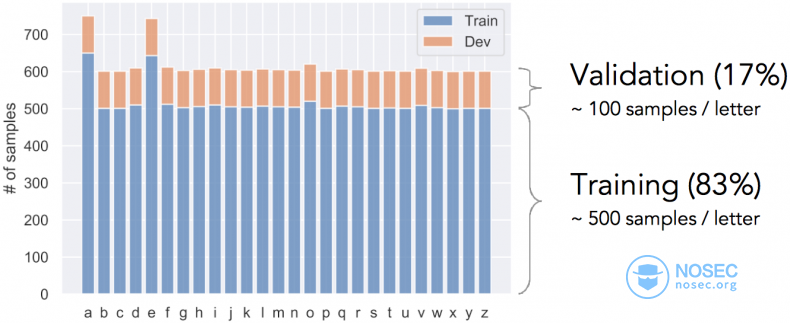
为了进行训练,我收集了大约16000个样本,确保每个字母至少有600个样本。
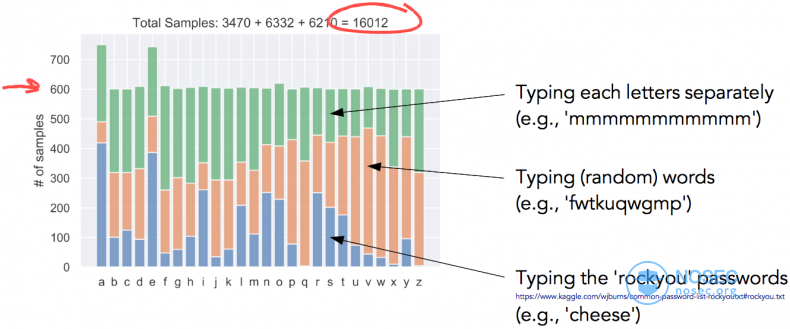
然后,将数据打乱分成训练集和验证集。每个字母大约有500个训练样本和100个验证样本。
因此,机器学习要做的事如下所示。
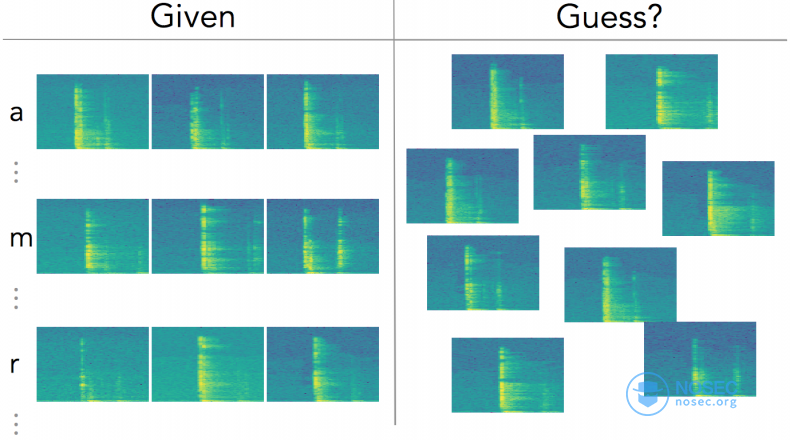
训练和验证
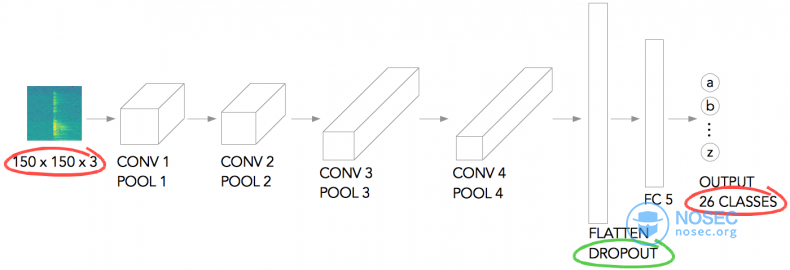
我使用了一个相当小而简单的网络结构(基于Laurence Moroney’s rock-paper-scissor example)。再如下图所示,将图像缩放到150×150像素,3个色彩通道。然后经过一系列卷积层+池化层,拉平(使用dropout防止过拟合),发送给一个全连接层,最后便是输出层。输出层有26个类,对应26个字母。
在TensorFlow中,模型如下:
model = tf.keras.models.Sequential([
# 1st convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
# 2nd convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# 3rd convolution
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# 4th convolution
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# Flatten the results to feed into a DNN
tf.keras.layers.Flatten(),
tf.keras.layers.Dropout(0.5),
# FC layer
tf.keras.layers.Dense(512, activation='relu'),
# Output layer
tf.keras.layers.Dense(26, activation='softmax')
])
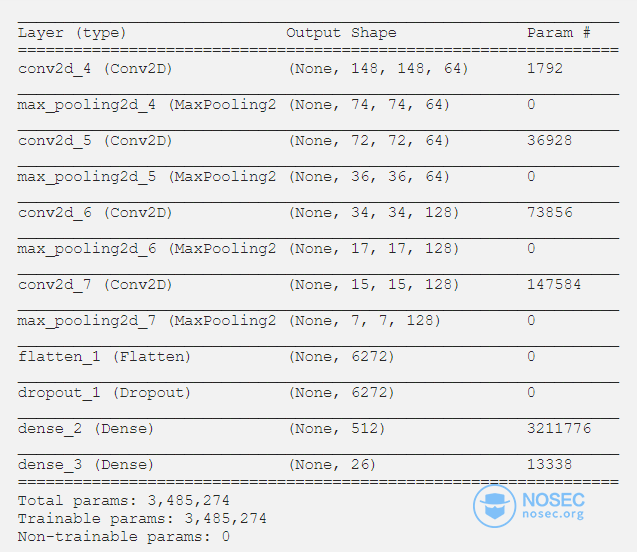
模型总结如下:
而训练结果如下图所示。在大约13个epoch中,大约达到了80%的验证精度和90%的训练精度。考虑到问题的复杂性和所使用网络结构的简陋,我觉得这种级别的准确性已经非常高。
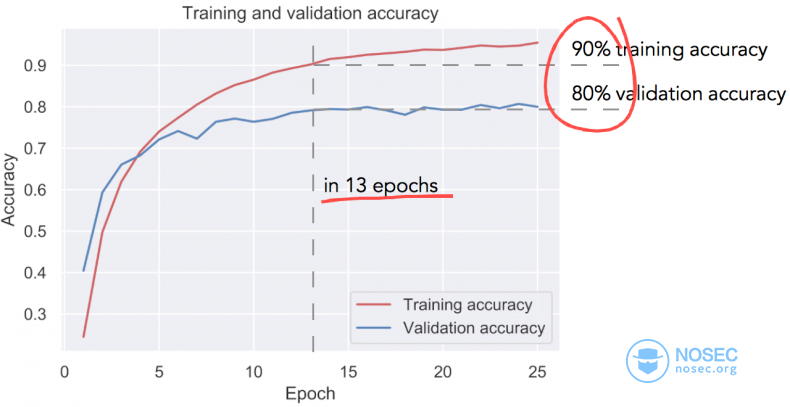
到目前为止,似乎一切都很顺利……但是,请注意这是字母级别的准确性,而不是单词级别的准确性。
为了破解密码,我们必须正确预测每一个字符,而不是大部分字符!
测试
因此,为了测试这个模型,我又从rockyou.txt中提取了200个不同的密码,然后使用我们刚刚训练出来的模型来猜测密码。
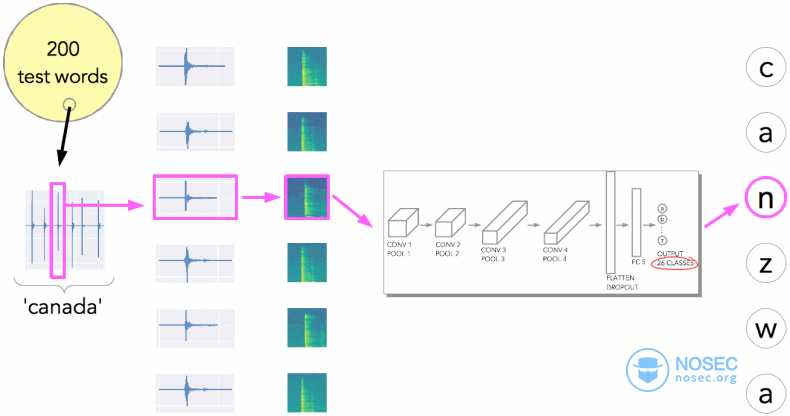
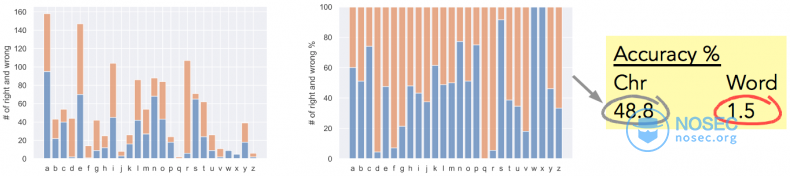
下图展示了测试的精准度。柱状图显示了字母级别的准确性(左边的图显示了正确和错误的数量,而右边的图显示了百分比)。最后发现字母级别的准确率约为49%,而单词级别的准确率为1.5%(200个测试单词只有3个完全正确)。
考虑这是我们第一次实验,1.5%貌似还不错,那么我们如何提高呢?
误差分析
让我们仔细分析到底哪里影响了准确率。

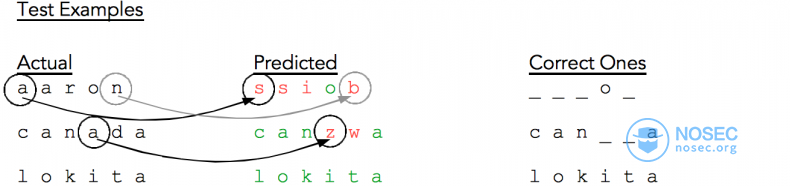
上图是一些样本测试结果。左边代表实际单词,中间代表机器预测的单词,红色表示预测错误,右边是预测准确的字母。
我们可以看到单词aaron只预测到了一个字母,canada猜对了大部分字母,lokita猜对了所有字母。
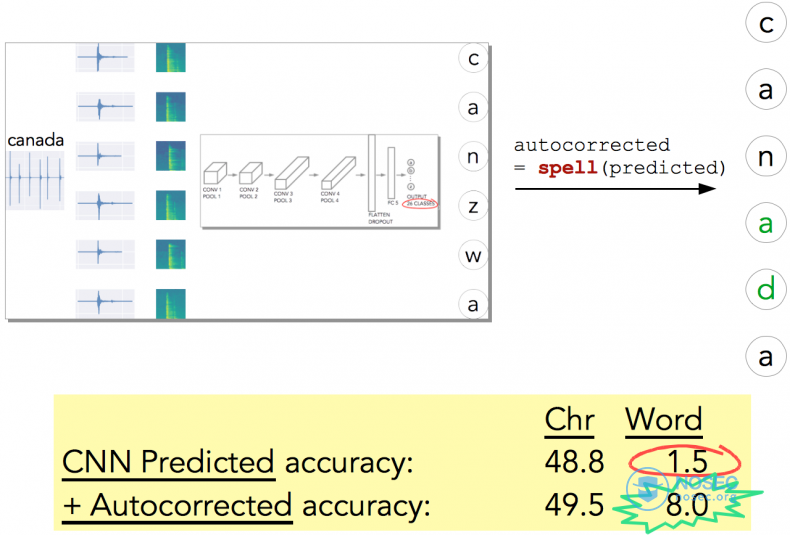
以canada为例,如果使用单词拼写检查函数进行处理,会有改善么?
确实有变化,准确率从1.5%提升到了8%!现在,一个相当简单的网络架构加上拼写检查器,就可以得到8%的预测准确率!
很快我又想到,应该使用某种序列模型(RNN?,Transformer?)去纠正单词错误,这样应该可以得到更高的单词准确性。这也许是我未来的研究方向。
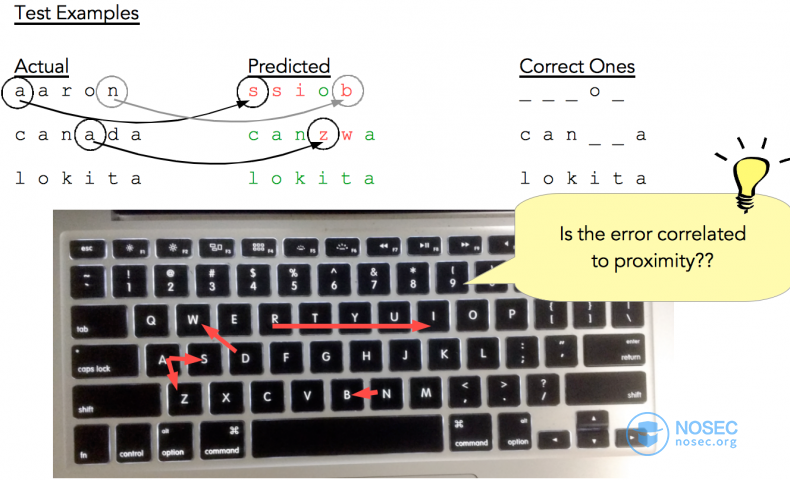
不过现在让我们回到测试结果,可以注意到字母a被预测为字母s,字母n被预测为字母b等等。
通过仔细观察键盘,我发现这种错误似乎和键盘中两个键的距离有关!
能将这种误差量化么?
下图显示了MacBook Pro上麦克风和键盘的位置,以及一些字母对应的识别错误字母。
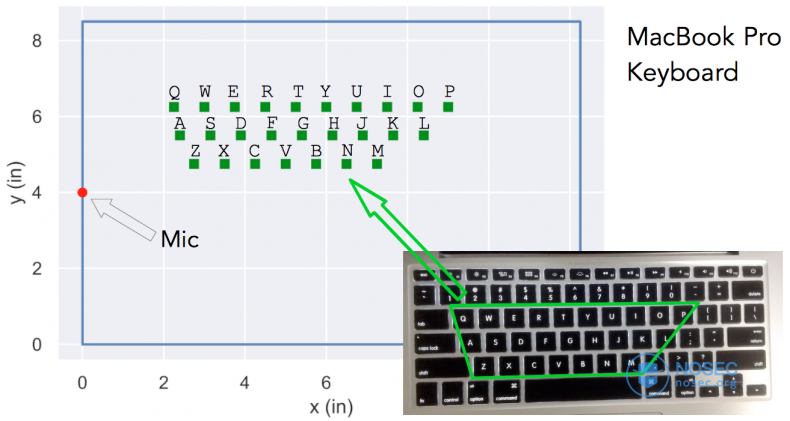
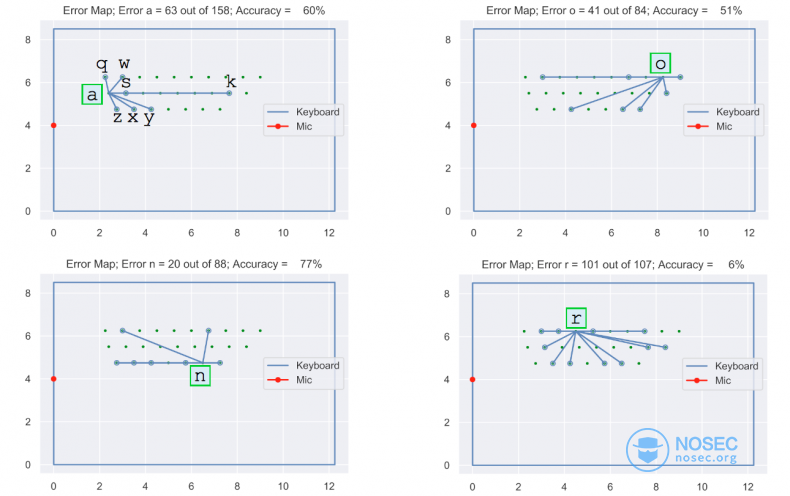
可以很明显的看出,字母a被错误地预测为z、x、y、k、s、w、q,其他情况也类似。
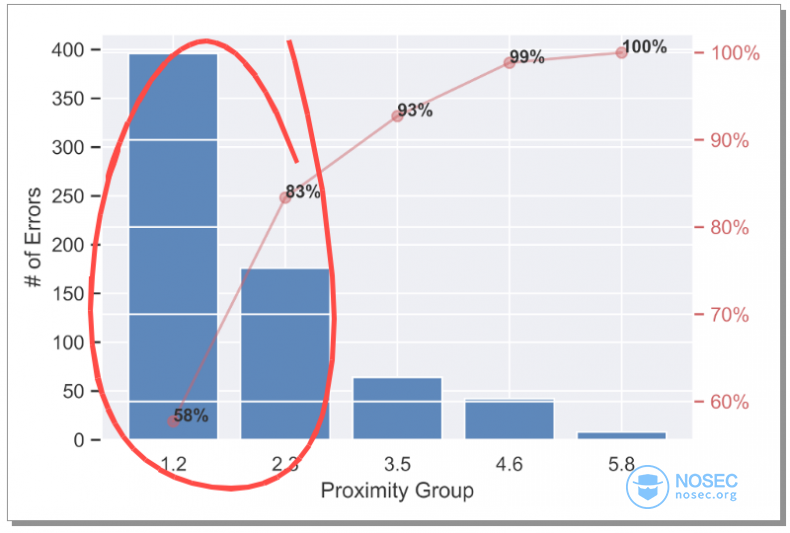
设d_ref为正确字母到麦克风的距离,d_predicted为预测字母到麦克风的距离,而d为d_ref与d_predicted差的绝对值。

下图是关于参数d和错误数量的直方图。我们可以看到一个非常明显的趋势——距离越近,越容易混淆,发生识别错误!这意味着我们可以通过更多的数据,更大的网络来提高模型的准确性。
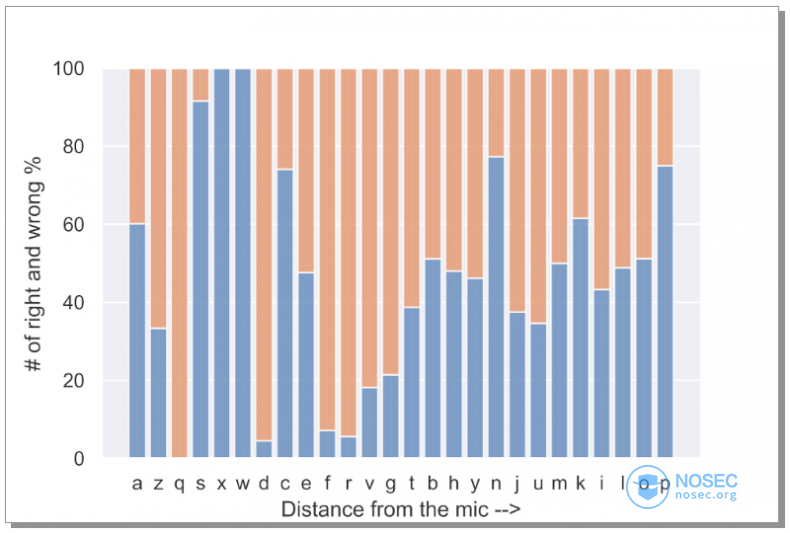
那么麦克风的位置又如何呢?误差是否与按键到麦克风的距离有关呢?为了研究这一点,我根据按键到麦克风的距离,做了递增顺序,展示准确率。结果发现两者关联不强。这样我们就可以把麦克风放在任意地方进行监听。
其它改进
除了上述改善方法,还有很多其他角度有待研究:
打字速度
特殊按键的(回车和大小写等)影响
背景噪音
输入源和麦克风品牌的影响
是否可以收集其他音源?(键盘震动?)
结论
敲打按键的声音确实可以被识别为字母,虽然当前准确性较低,但只是一个简单的实验,后续如果加强纠错功能和扩大样本数量,也许会得到理想的结果。两个相邻的按键容易被混淆,不过这和麦克风的位置无关。
GitHub:https://github.com/tikeswar/kido
本文由白帽汇整理并翻译,不代表白帽汇任何观点和立场
来源:https://towardsdatascience.com/clear-and-creepy-danger-of-machine-learning-hacking-passwords-a01a7d6076d5



最新评论